高级节点
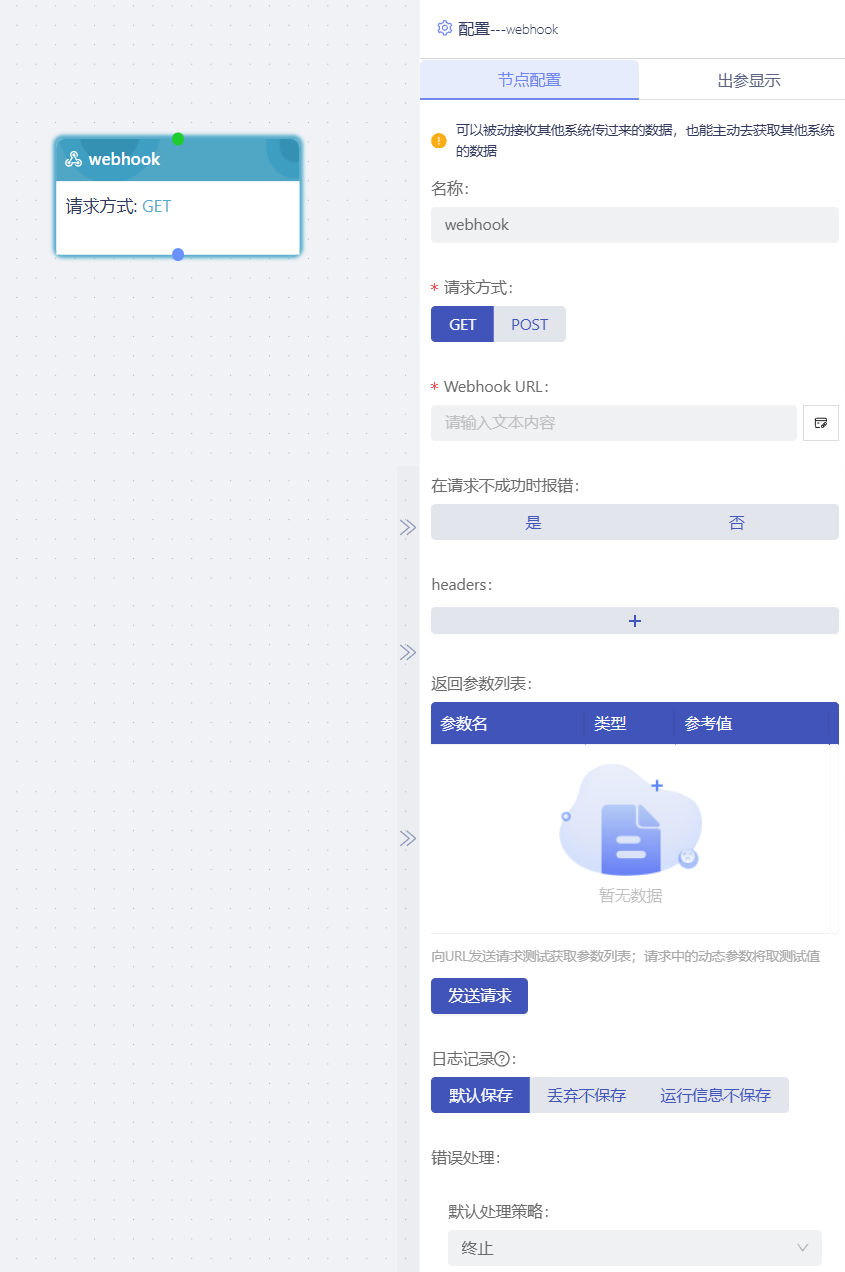
webhook
流程中的webhook功能,即可以被动接收其他系统传过来的数据,也能主动去获取其他系统的数据
- body: 请求接口需要传的参数,一般更新或者是新增的接口传,当值为变量时,配置中下方的发送请求时可通过设置的模拟值来模拟返回结果,为后续节点绑定参考使用。
执行指令
指令用于设备远程控制;当节点触发后,执行指令,配置如图所示:
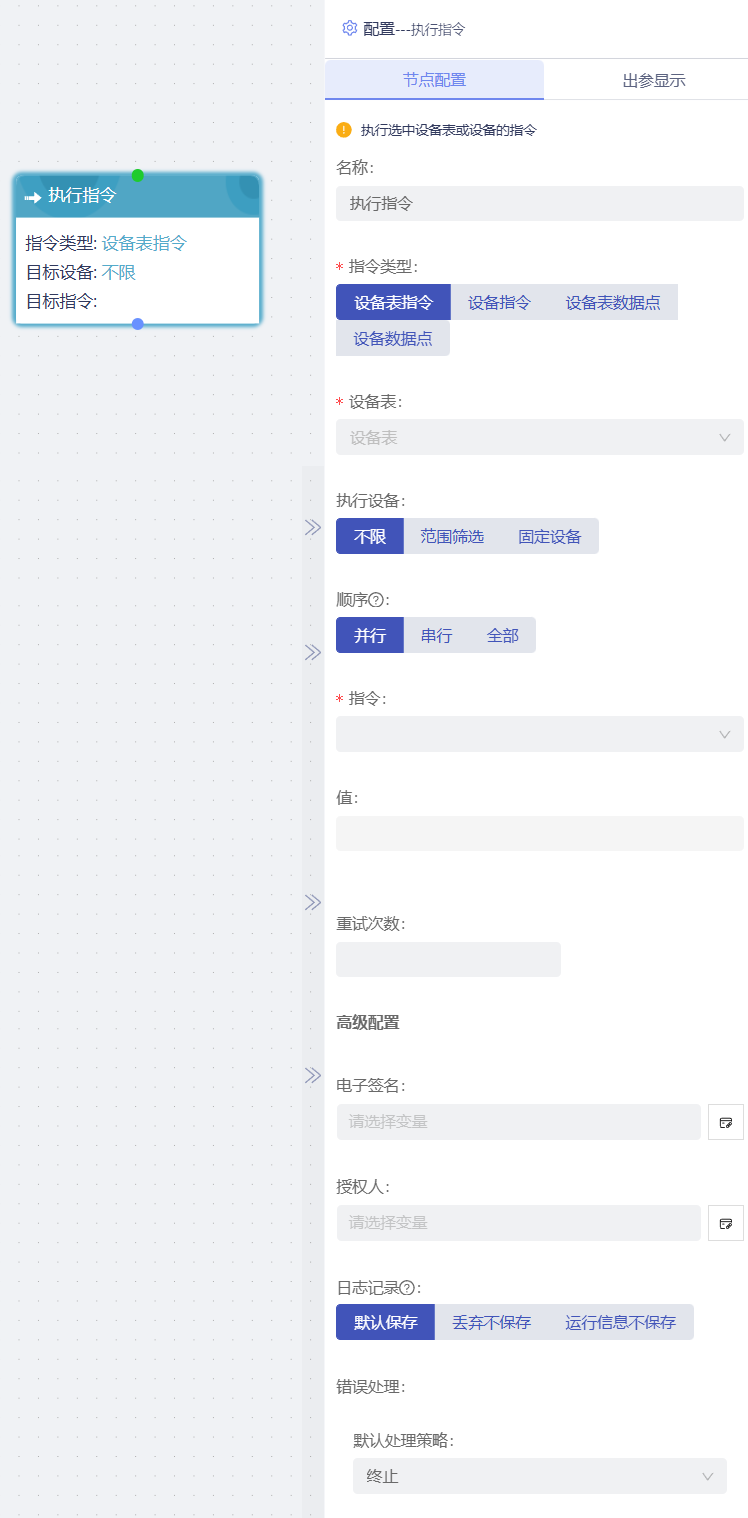
指令类型: 包括设备表指令、设备指令、设备表数据点指令、设备数据点指令。
设备表指令
确认指令范围,点击设备表指令,选择目标设备表和该设备表下的设备,选中设备表后,可按照范围筛选设备也可直接选择设备,点击选择指令即可。
- 设备表:选择需要执行指令的设备表;
- 执行设备:选择需要执行指令的设备:
- 不限:是指全部设备;
- 范围筛选:可以按照过滤条件进行定义,符合条件的的设备执行指令;
- 固定设备:可以多选,选择需要执行指令的设备。
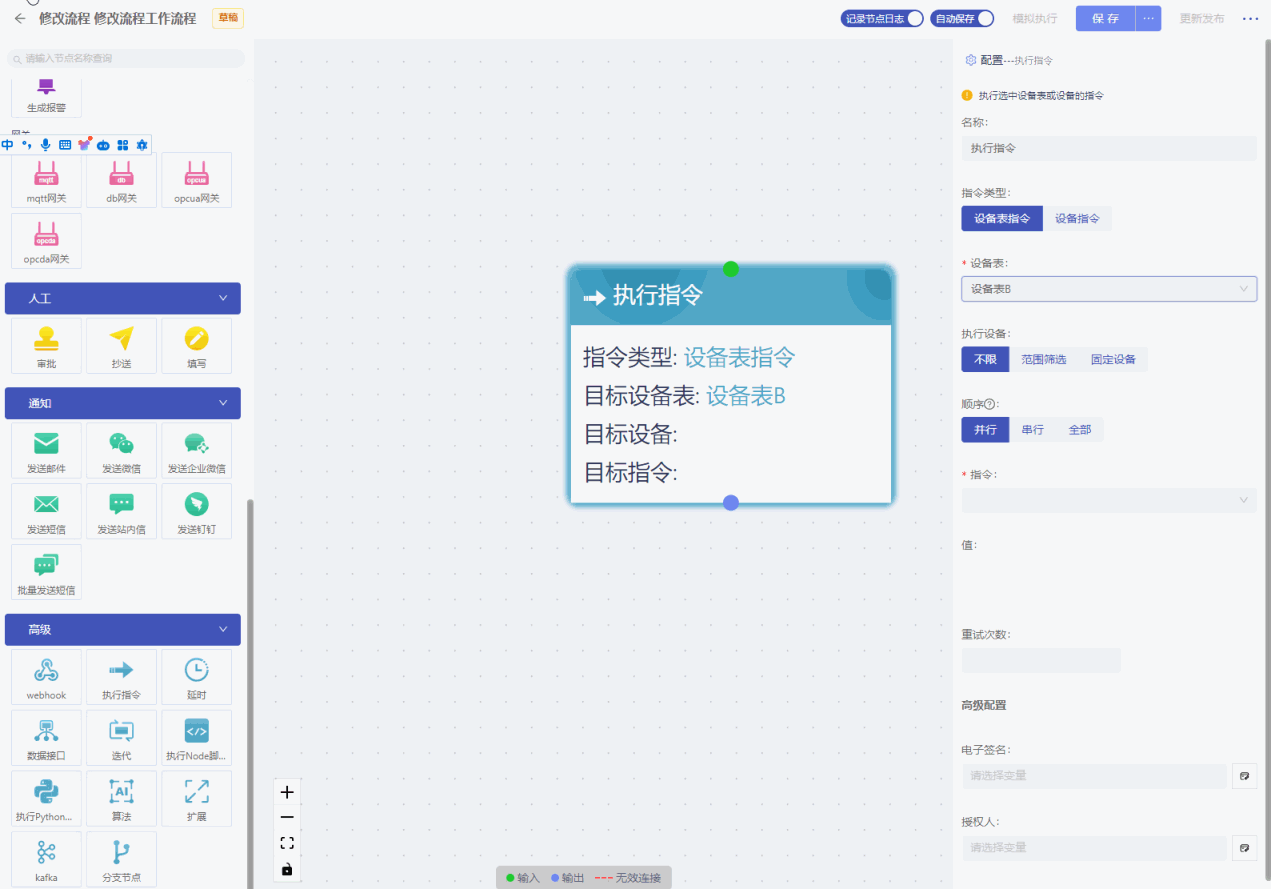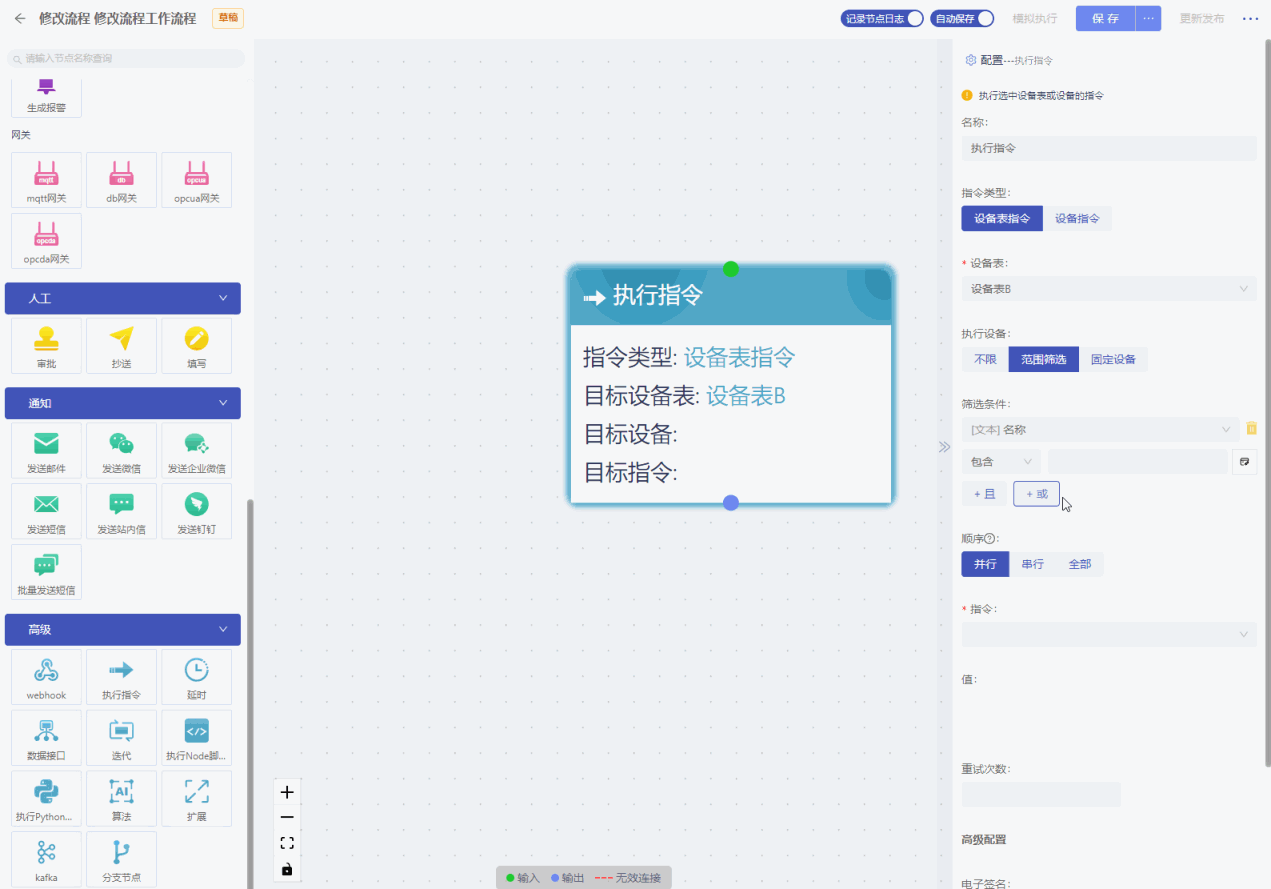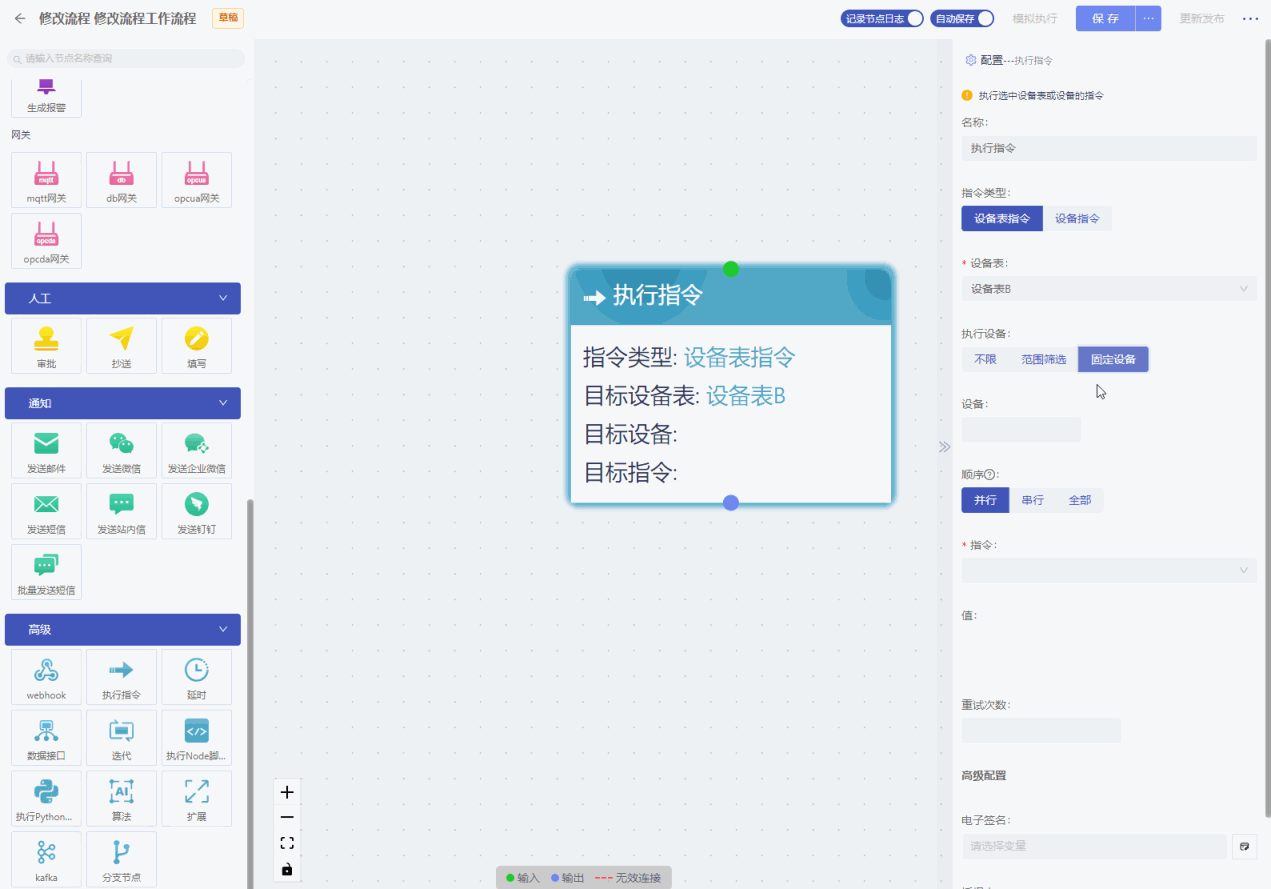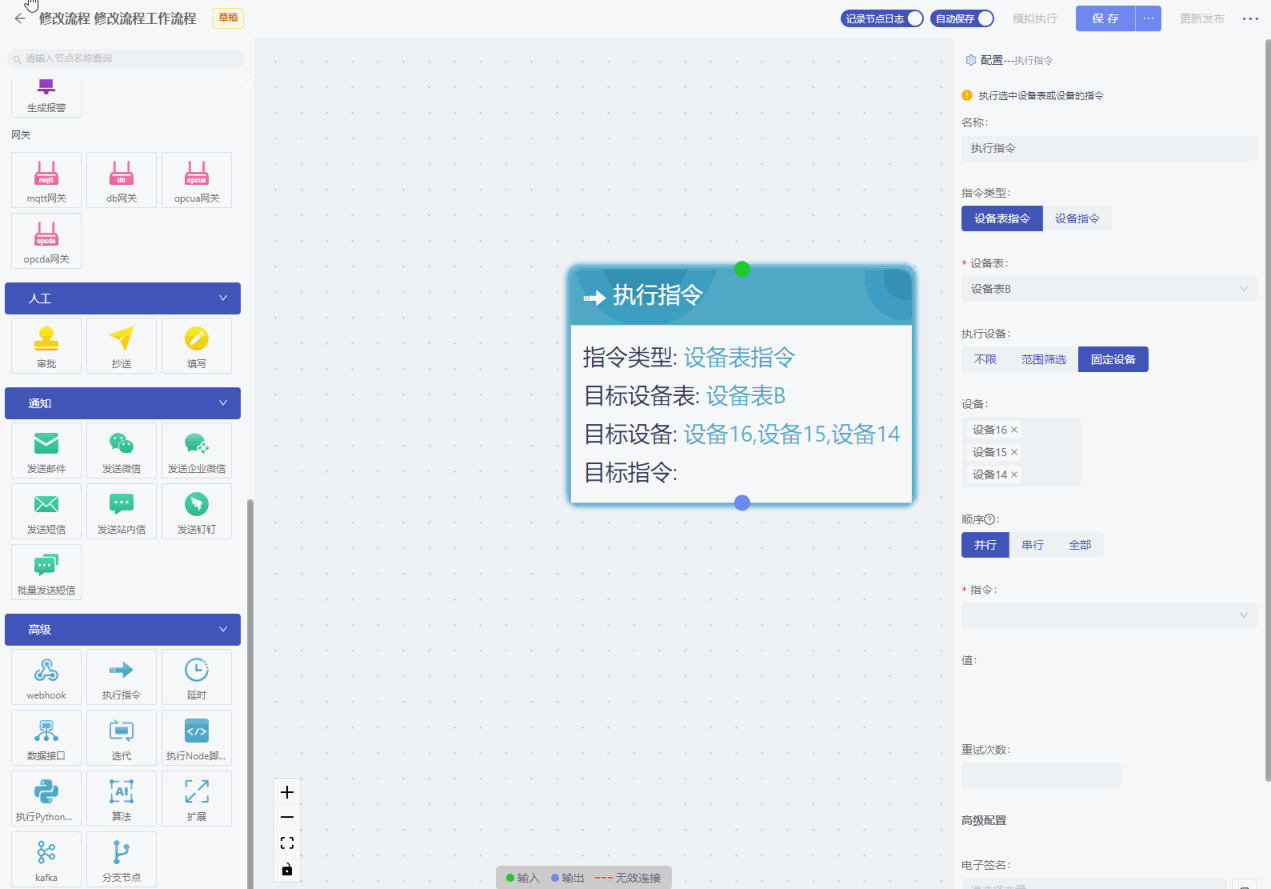
- 顺序:包括并行、串行、全部。
- 并行: 满足条件的设备同时执行指令
- 串行: 满足条件设备只能一个一个执行指令,例如a设备指令执行完在执行b设备指令:
- 等待时间(毫秒):当顺序选择串行时,显示等待时间配置项,设置指令串行执行的时间间隔;
- 全部: 配置全部指令下发给驱动,驱动负责串行还是并行或者其他的执行方式,取决于具体驱动的实现

- 指令: 选择具体指令;
- 值:输入执行指令的值:
- 重试次数:第一次执行指令失败后,可以继续执行指令的次数,定义次数范围内若指令执行成功,若有剩余次数,不会继续重试执行
- 高级配置:当执行指令上方节点为审批节点,且审批节点开启电子签名后,执行指令节点可绑定审批节点中的电子签名、授权人的变量,则执行指令日志中会显示电子签名及授权人的信息。
- 电子签名、授权人:绑定审批节点中的相关变量。
设备指令
设备的选择用来确认指令范围,直接选择设备,可选择一个,也可选择多个

设备表数据点指令
选择开启读写功能的设备表数据点执行指令。当设备表的数据点开启读写功能后,该数据点为指令数据点,可通过向数据点中写入值进行执行指令,如下图所示,modubs驱动下的数据点开启读写功能:
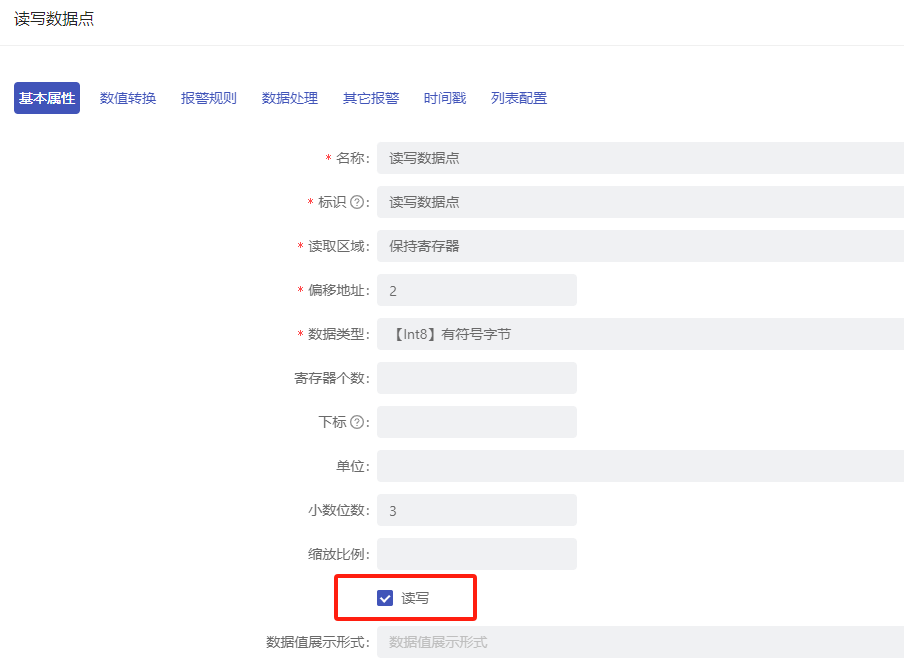
- 设备表:选择设备表,注意这里的表需要选择开启读写功能数据点的设备表;
- 数据点:选择开启读写功能的数据点,这里只展示已勾选读写属性的数据点;
设备数据点指令
选择开启读写功能的设备数据点执行指令。
延时
延时节点触发后,上一节点触发信息会在指定时间后传送给下一节点,设置如图所示:
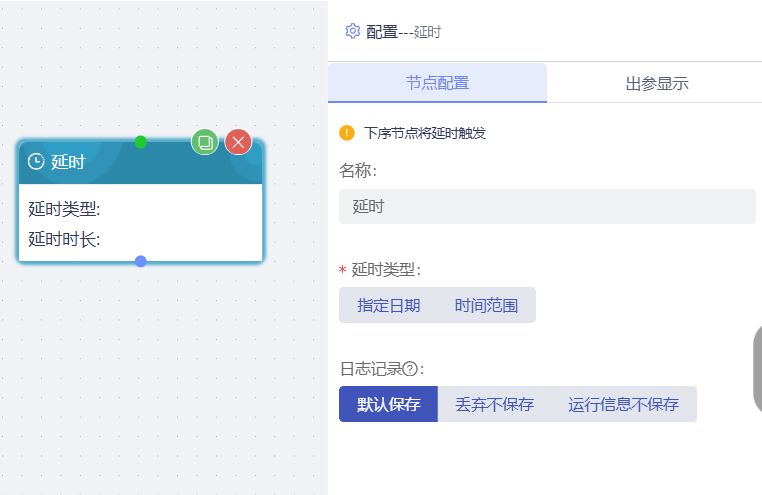
延时类型:包括指定日期和时间范围,指定日期是指在指定日期触发并进行流转到下一流程节点,时间范围是指经过一段时间后触发并进行流转到下一流程节点;
例如,当指定日期为2022年7月15日22时22分22秒时,则上一节点的触发信息会在2022年7月15日22时22分22秒传递给下一节点。
注意: 延时时间不能超过100天,延时配置均支持绑定。
设置变量
用于创建或更新变量,存储流程中使用的值。可以输出设置的变量值,供后续节点绑定使用。包括基础变量操作、列表变量操作、对象变量操作。
基础操作
基础操作可设置变量、删除变量、查询变量值。
- 设置变量:设置新变量,后续节点可以选择使用该变量。
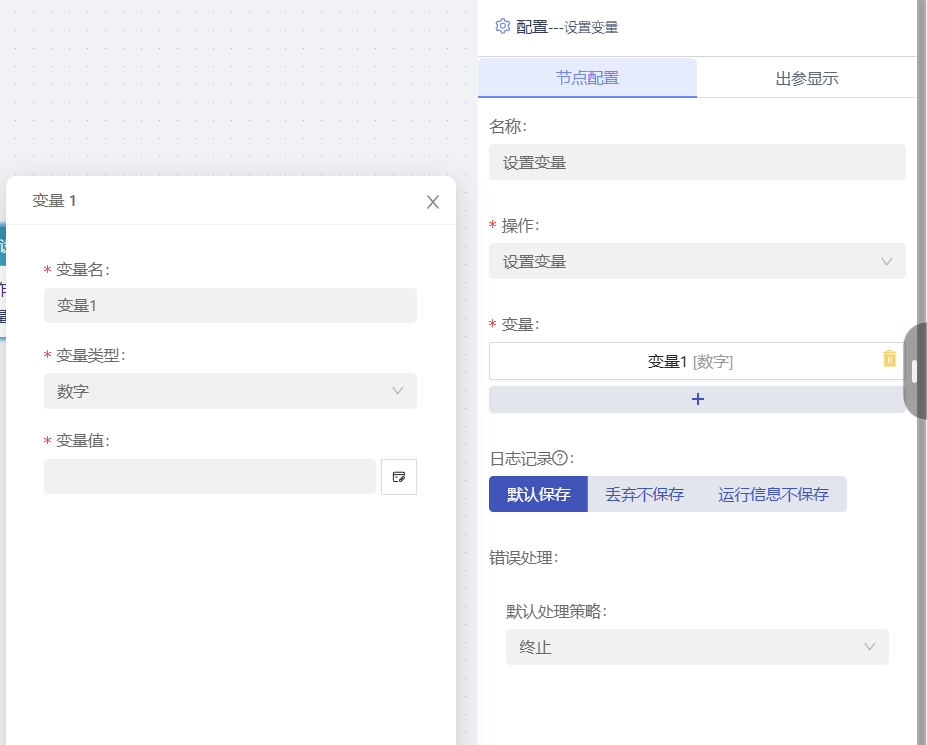
- 设置变量:可设置多个变量,变量类型支持字符串、数字、布尔、对象、数组,变量值支持绑定前序节点及系统变量值;多个变量名称不可重复,已添加的变量以“变量名[变量类型]”的格式显示名称。
- 错误处理:包括终止、忽略和重试。重试需设置重试后的规则,包括终止和忽略。
- 若终止,则发生错误时,流程终止。
- 若忽略:则发生错误时,流程忽略当前节点,进行下一节点流转。
- 若重试,则发生错误时,该节点会重试,根据重试后的规则进行处理,若仍然失败,则终止或忽略。
- 删除变量:删除前序节点中的变量。
- 变量名:输入前序节点的变量名,流程成功时会删除对应变量。
- 查询变量值:查询前序节点的变量值。
- 变量名:输入前序节点的变量名,查询对应变量值。
- 默认值:当查询变量名或变量值不存在时,返回默认值。默认值设置同变量设置。
- 变量名无效:选择变量名无效时,处理方式,包括运行成功,返回默认值和运行失败,节点报错。
列表操作
列表操作可设置列表插入元素、删除列表元素、更新列表元素、查询列表元素。
- 列表插入元素:选择已有的数组格式的变量进行元素的插入。
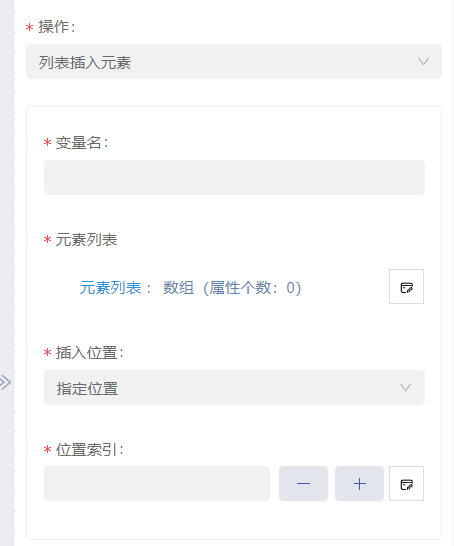
- 变量名:输入前序节点中的数组变量名,在该变量中插入新的变量。
- 元素列表:设置需要插入的元素列表;
- 插入位置:设置元素的插入位置,包括列表头部、 列表尾部和指定位置;
- 位置索引:指定位置需设置位置索引,只可输入大于等于0的正整数。其中,0代表数组中的第一个元素位置,依此类推。
- 删除列表元素:选择已有的数组格式的变量进行元素的删除操作。
- 变量名:输入前序节点的数组变量名,流程成功时会删除对应数组变量。
- 删除元素:选择元素的位置,包括列表第一个元素、列表最后一个元素和指定位置。
- 位置索引:指定位置需设置位置索引,只可输入大于等于0的正整数。其中,0代表数组中的第一个元素位置,依此类推。若输入的位置索引超出数组范围,该节点将执行错误处理。
- 更新列表元素:选择已有的数组格式的变量进行元素的更新操作。
- 变量名:输入前序节点中的数组变量名,在该变量中更新元素。
- 更新位置:选择元素的位置,包括列表第一个元素、列表最后一个元素和指定位置。
- 位置索引:指定位置需设置位置索引,只可输入大于等于0的正整数。其中,0代表数组中的第一个元素位置,依此类推。若输入的位置索引超出数组范围,该节点将执行错误处理。
- 更新后的元素:同设置变量操作。
- 查询列表元素:选择已有的数组格式的变量进行元素的查询操作。
- 变量名:输入前序节点中的数组变量名,在该变量中查询元素。
- 查询位置:选择元素的位置,包括列表第一个元素、列表最后一个元素和指定位置。
- 位置索引:指定位置需设置位置索引,只可输入大于等于0的正整数。其中,0代表数组中的第一个元素位置,依此类推。若输入的位置索引超出数组范围,该节点将执行错误处理。
- 索引不在列表范围:索引不存在时,处理方式,包括运行成功,返回默认值和运行失败,节点报错。
对象操作
对象操作可设置键值对、删除键值对、查询键值对。
- 设置键值对:指定键和对应的值,更新或创建对象中的键值对。

- 变量名:设置键值对变量的名称;
- 键值对列表:设置键值对列表;
- 删除键值对:选择对象中的键进行删除操作。
- 变量名:输入前序节点的键值对变量名,流程成功时会删除对应键值对中指定键的数据。
- 键:输入需要删除的键。
- 查询键值对:选择对象中的键进行查询操作。
- 变量名:输入前序节点中的键值对变量名,在该变量中查询对于键的值。
- 键:输入需要查询的键。
- 键不存在:键不存在时,处理方式,包括运行成功,返回默认值和运行失败,节点报错。
子流程响应
定义子流程需返回至其他流程(主流程)的参数结构及数据。
例如:子流程为计算流程,将主流程的数据进行计算,并将计算结果返回给主流程,需要在子流程中添加【子流程响应】节点,在节点中定义需返回给主流程的参数结构,参数需写入或绑定数据,供主流程使用。
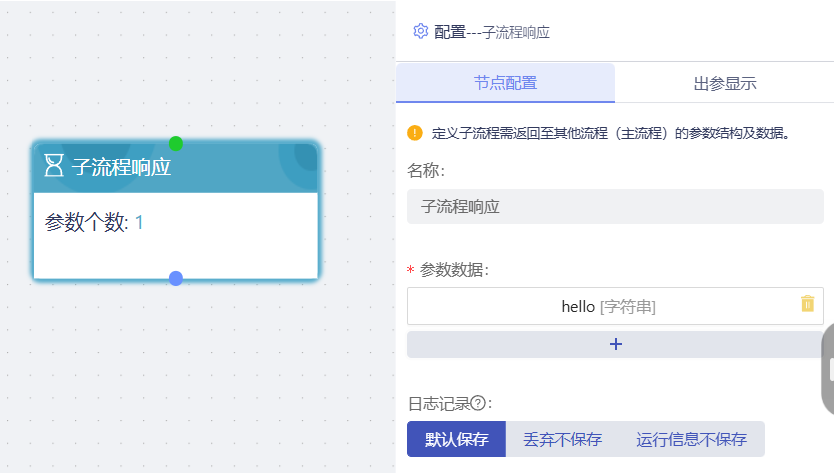
- 参数数据:必填,定义参数格式及数据,同【设置变量节点】的变量设置。
- 只有当流程起始节点为【子流程触发】时,【子流程响应】才可拖入到画布中。
- 一个子【流程触发节点】,只能增加一个【子流程响应节点】。
调用子流程
当流程中需要调用子流程时,使用的节点,最多支持三层嵌套调用。
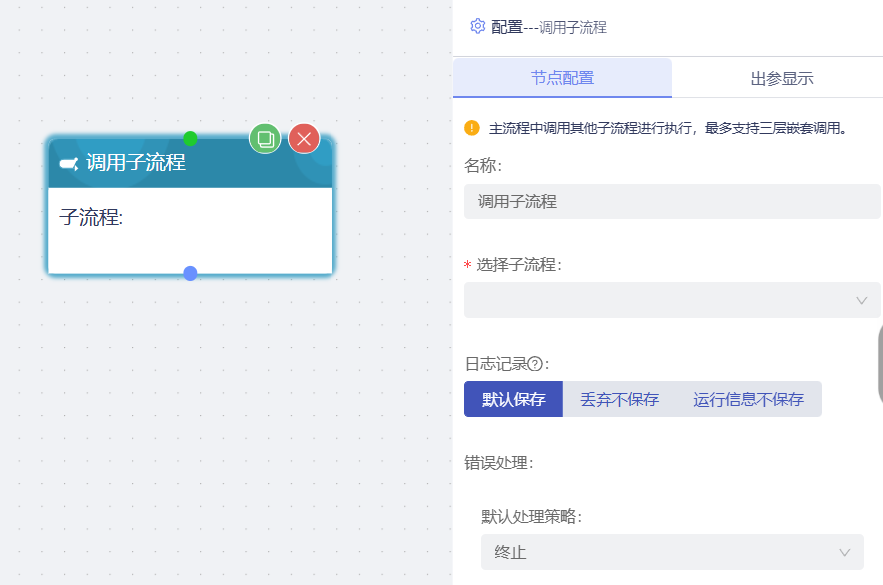
- 选择子流程:必填项,单选,选择平台中已经发布在有效期的且起始节点为【子流程触发】且子流程嵌套小于3级的流程。
- 触发子流程数据:当选择子流程后,展示触发子流程数据的属性配置,若子流程未配置参数,则触发子流程数据下,提示无触发参数数据。若配置了参数列表,则展示配置的参数对应表单。
- 若子流程设置了子流程响应的参数数据,主流程在后续节点中可以绑定这些参数。
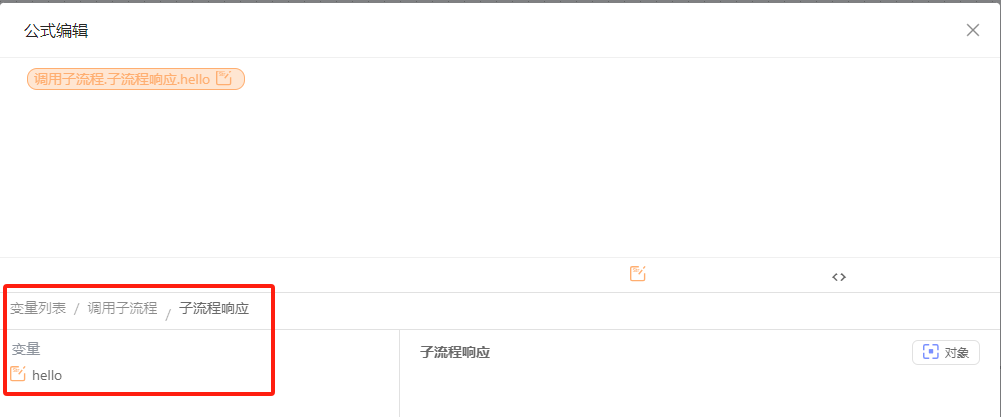
- 当主流程调用一个嵌套2层的子流程时,只能获取子流程的直接输出,无法获取更深层的子流程数据。
- 调用子流程时,子 流程已经为2层嵌套,主流程发布后,子流程中的子流程又嵌套了,导致主流程调用的子流程出现3层以上嵌套,易导致同时执行数量过多,流程卡顿。
数据接口
选择【设备配置】-【数据接口】功能中定义的接口,流程执行的时候,会去调用选择的接口,接口返回的数据,可以供后续节点绑定使用
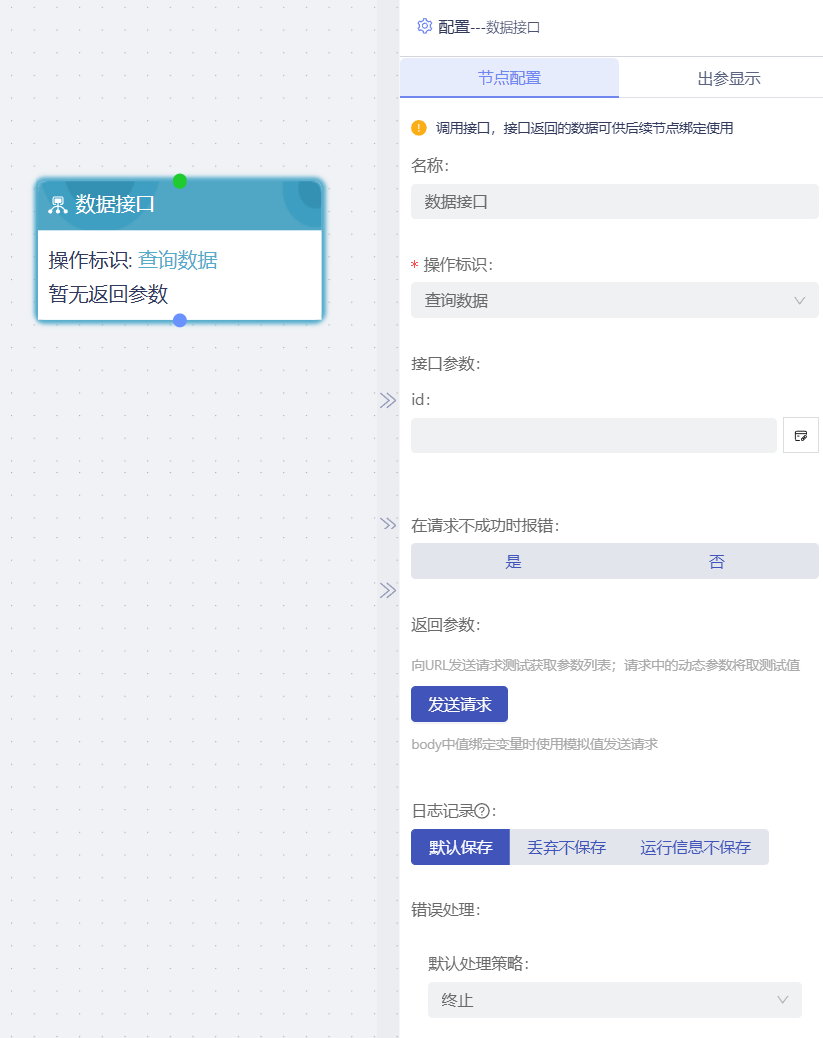
body: 请求接口需要传的参数,一般更新或者是新增的接口传,当值为变量时,配置中下方的发送请求时可通过设置的模拟值来模拟返回结果,为后续节点绑定参考使用
操作标识: 选择【设备配置】-【数据接口】功能中定义的接口
返回参数: 向URL发送请求测试获取参数列表;取值中的动态参数将取测试值
发送请求: body中值绑定变量时使用模拟值发送请求
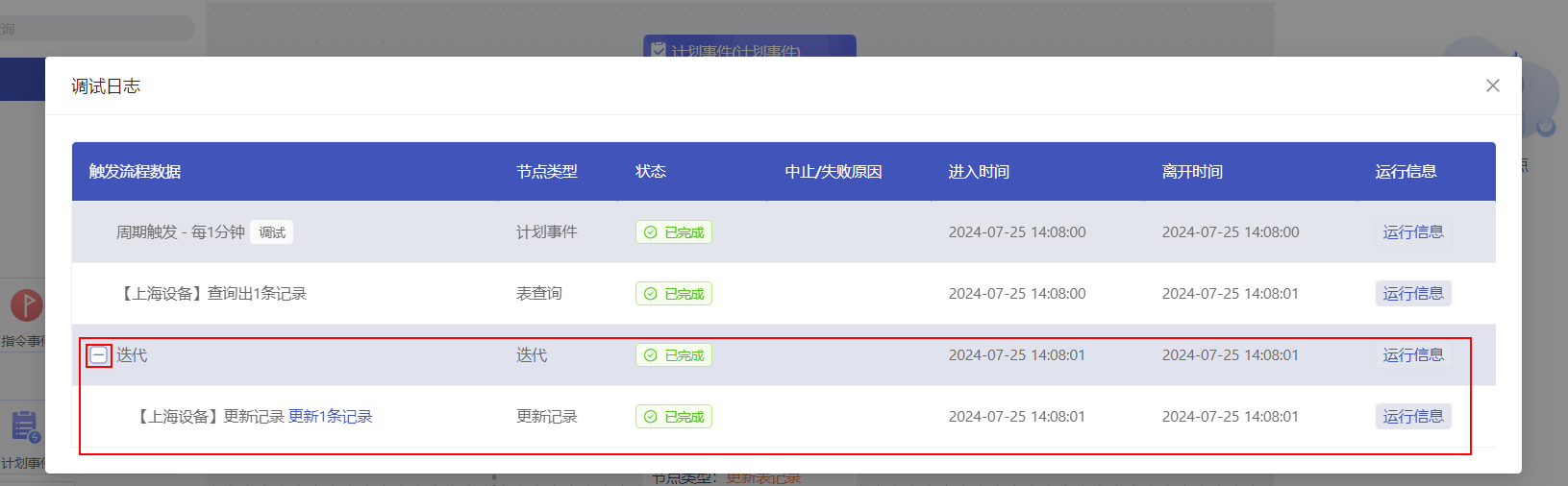
迭代
用于依次或同时处理前序节点输出的数组数据。例如,前序节点中有一个包含3个子元素的数组变量,当迭代节点绑定该数组时,迭代节点中其他节点的操作将执行3次。
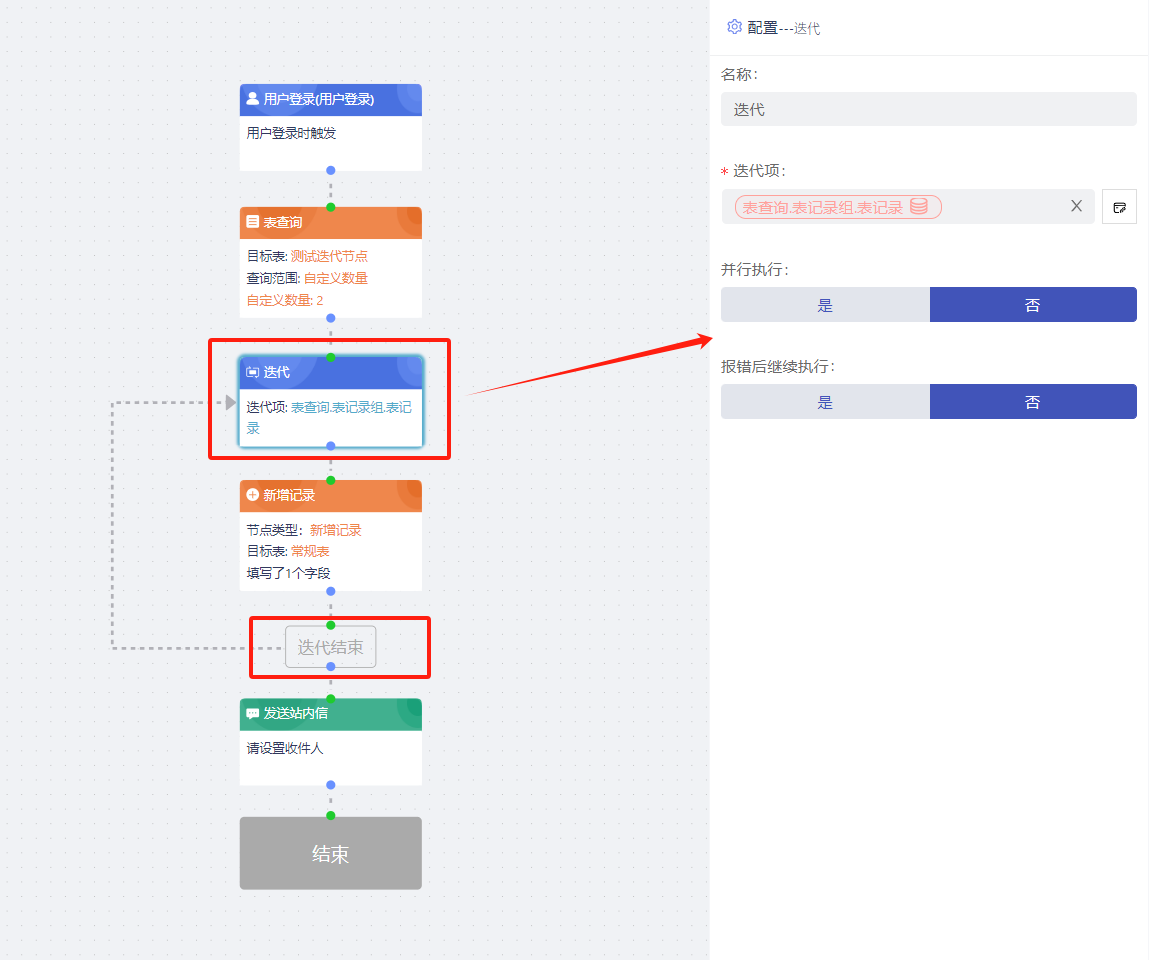
并行执行: 选择是时,迭代数组并行执行,否为串行执行。并行:同时执;串行:逐个执行。
报错后继续执行:选择是时,迭代节点报错后继续执行,否为迭代节点报错后不执行。
注意:
- 只有在迭代节点和迭代结束节点之间的节点会进行迭代,迭代结束节点之后的节点为迭代外的节点,不进行迭代。
- 迭代节点的日志可以进行折叠和展开
扩展节点
当流程中节点功能不满足客户需求时,可通过二次开发扩展功能,在扩展节点中选择相应的扩展服务,详情见SDK流程扩展节点接入schema说明、go流程扩展节点接入schema说明、NODE流程扩展节点接入schema说明
分支节点
分支节点根据设定的条件执行不同的分支操作,当没有满足条件时执行默认分支,确保流程不会出现阻塞或中断的情况。
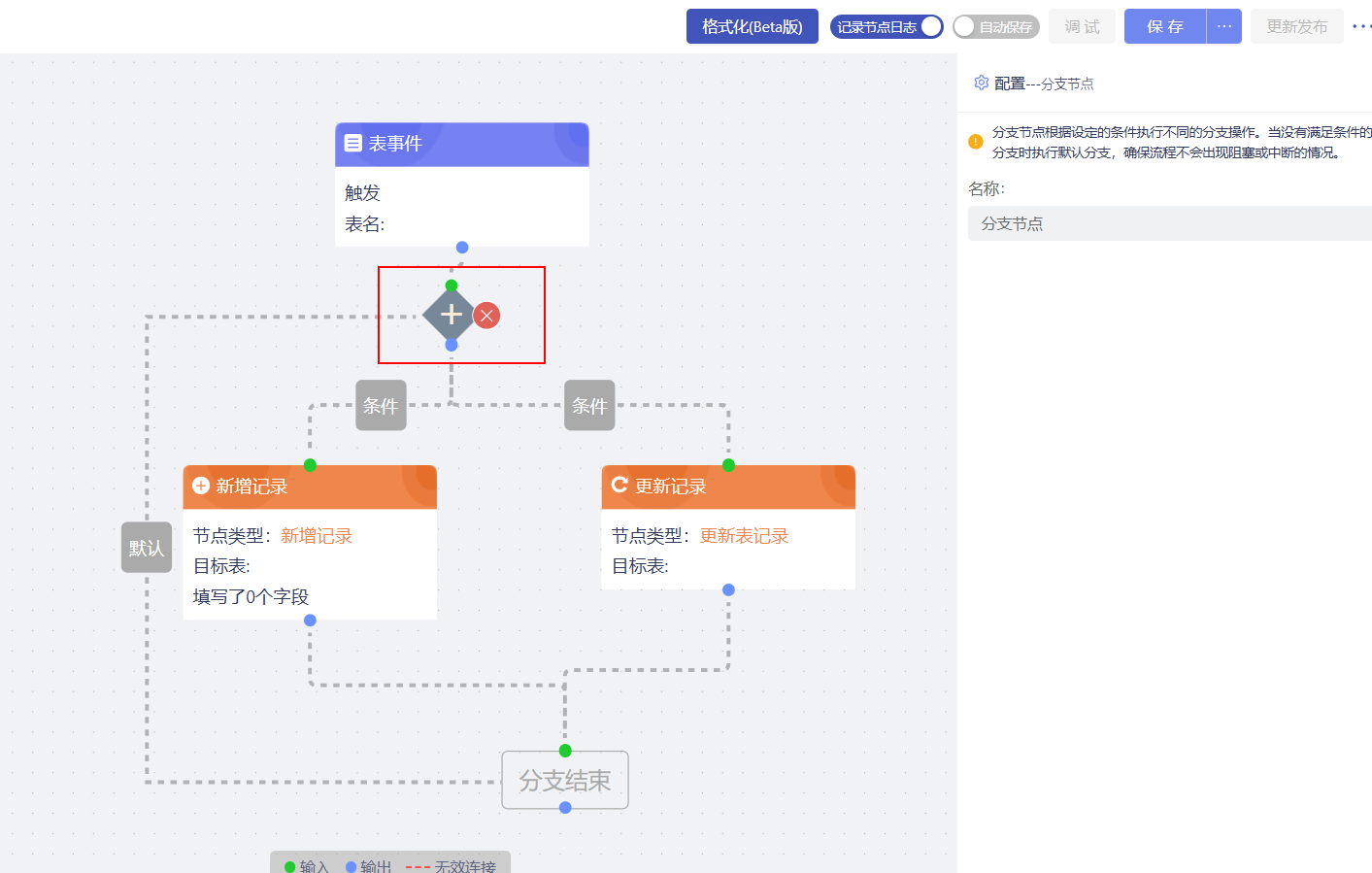 分支条件中自带一个默认条件,当不满足分支条件时可直接向下执行流程。
分支条件中自带一个默认条件,当不满足分支条件时可直接向下执行流程。
分支内的节点不可以直接连接到流程的结束节点,需连接分支内的结束节点。
分支节点日志:可通过展开分支节点日志查看分支内的流程日志。

- 条件设置
点击条件分支中的条件框,即可设置分支条件。条件的定义方式有两种: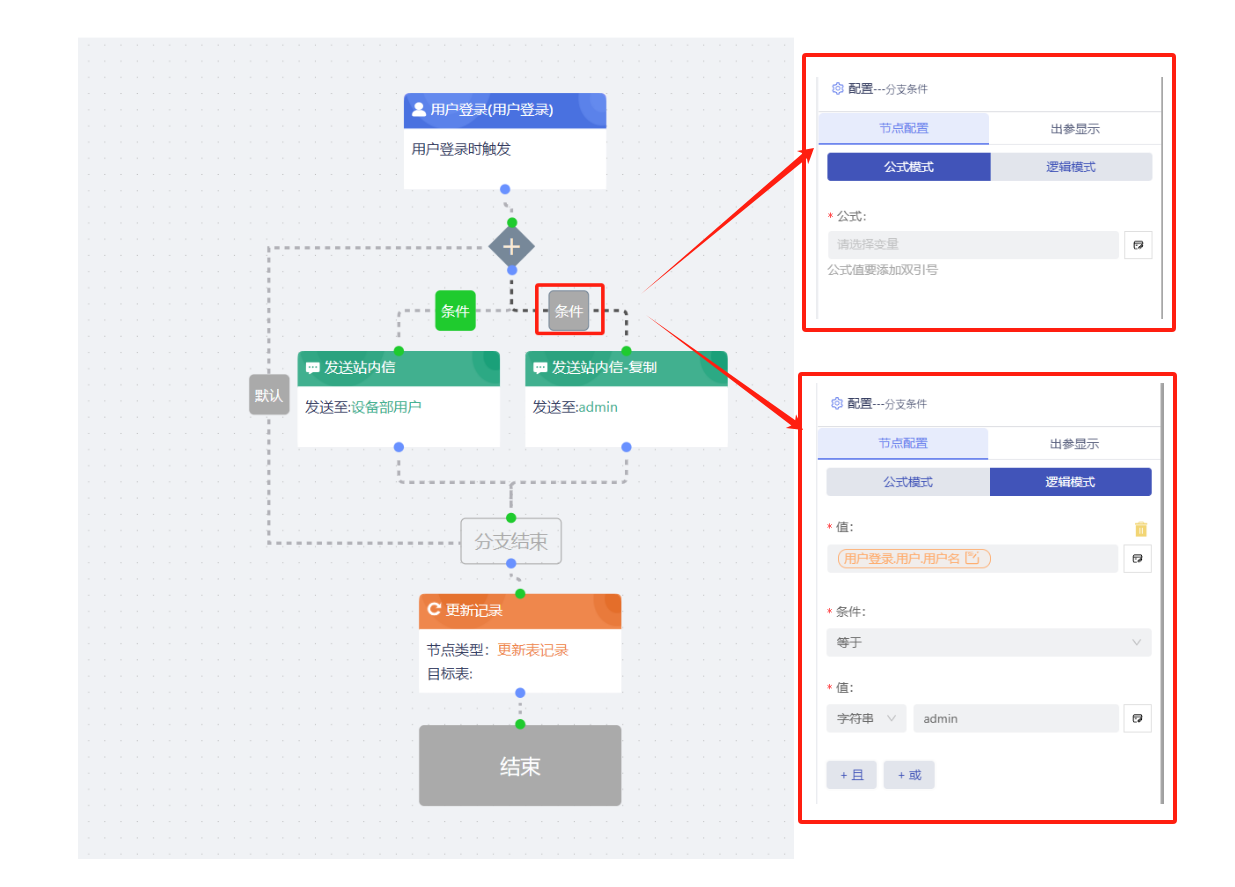
- 公式模式:使用公式编辑器来定义条件。
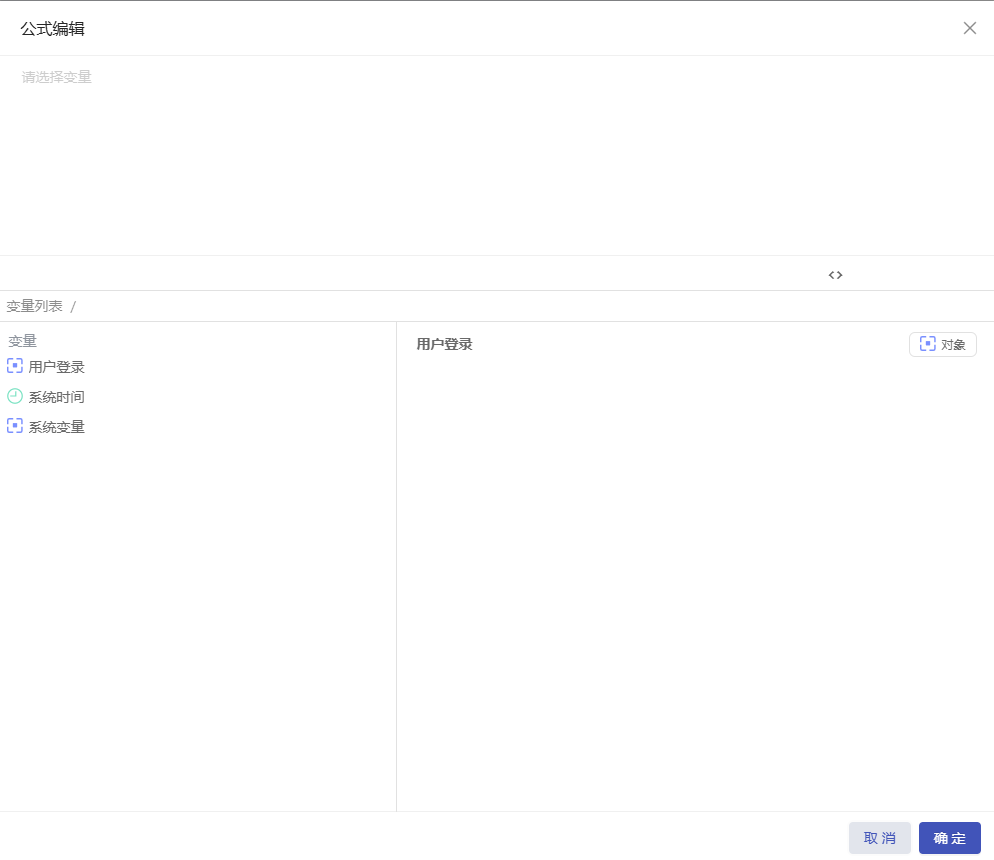
- 逻辑模式:点击“添加条件”按钮,添加逻辑判断组件,通过定义条件的左值、逻辑运算符和右值来设置条件。
- 条件左值。运行时,根据条件对左值、右值进行计算,将计算结果作为当前分支条件的结果。
- 条件:条件左值和条件右值的运算规则。运行时,根据条件对左值、右值进行计算,将计算结果作为当前分支条件的结果。条件包括:等于、不等于、大于、大于或等于、小于、小于或等于、包含、不包含、以...开始、不以...开始、以...结束、不以...结束、为Undefined、不为Undefined、存在、不存在、为true、为false。
- 条件右值:条件右值.运行时,根据条件对左值、右值进行计算,将计算结果作为当前分支条件的结果。
- 条件组合操作符: 分支条件列表组合操作符。或:一个条件为真,执行该分支。且:每个条件都为真,执行该分支
操作流程:
- 在需要进行条件判断执行不同流程节点是,添加分支节点进行条件判断。
- 设置每个分支的判断条件。
- 设置每个分支节点的下一个节点操作
- 条件设置完毕时,背景颜色由灰色转变为绿色
执行Node脚本
- 功能简介 脚本变量(固定值或者前序节点的变量)以参数的形式传给脚本,脚本执行逻辑,把执行结果以变量的形式输出给后续节点使用。
- 演示示例
- 通过设备数据事件节点触发流程,把数据点的值传给脚本节点,执行脚本逻辑后,把结果输出给更新变量节点,达到修改平台数据字典中的系统变量的值的效果。
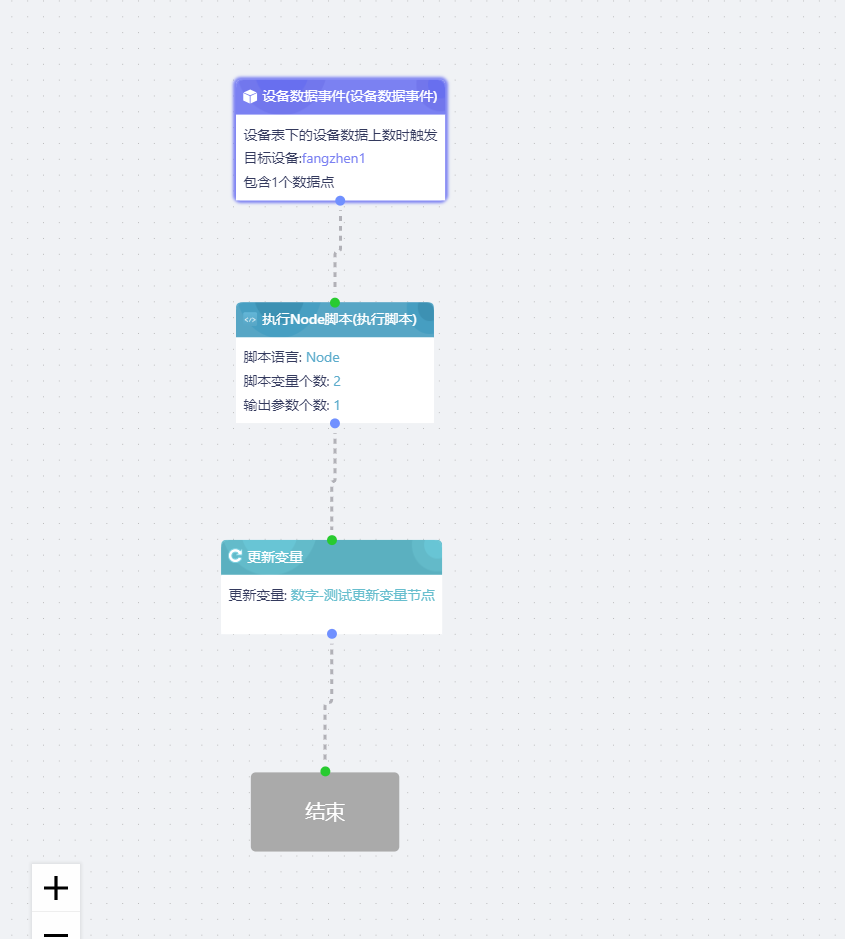
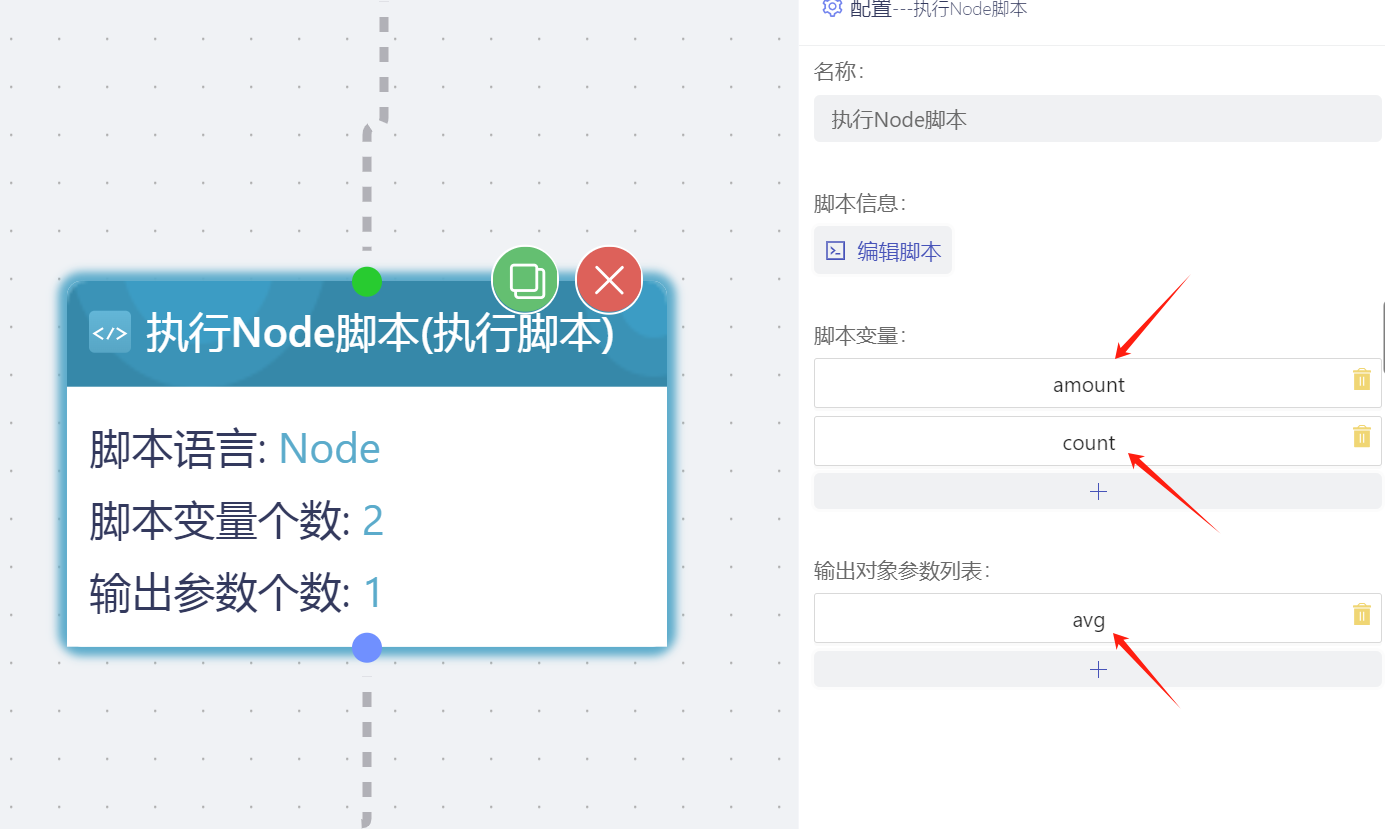
- 执行脚本节点定义了两个脚本变量amount和count和一个输出参数avg,该字段类型是数字,amount绑定的前序节点的数据点的值,count是固定值2。
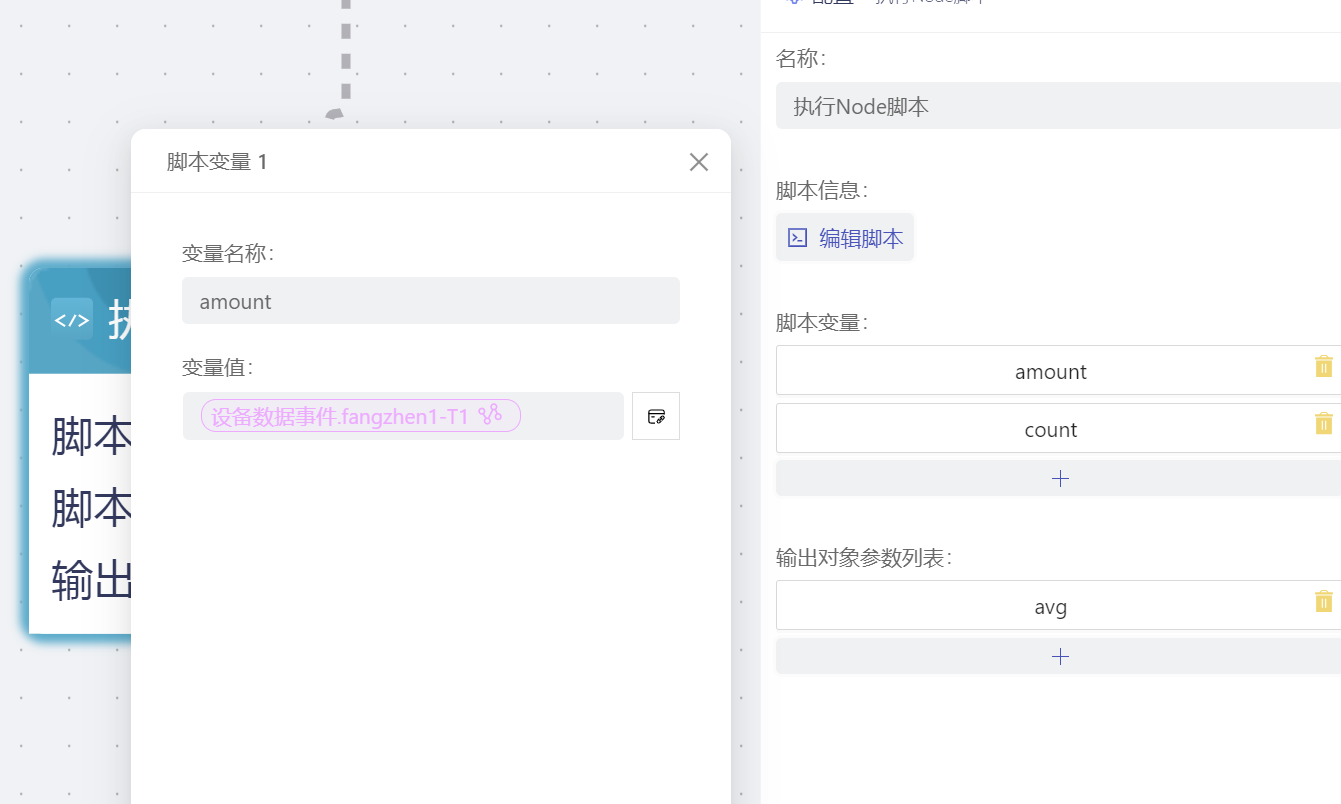
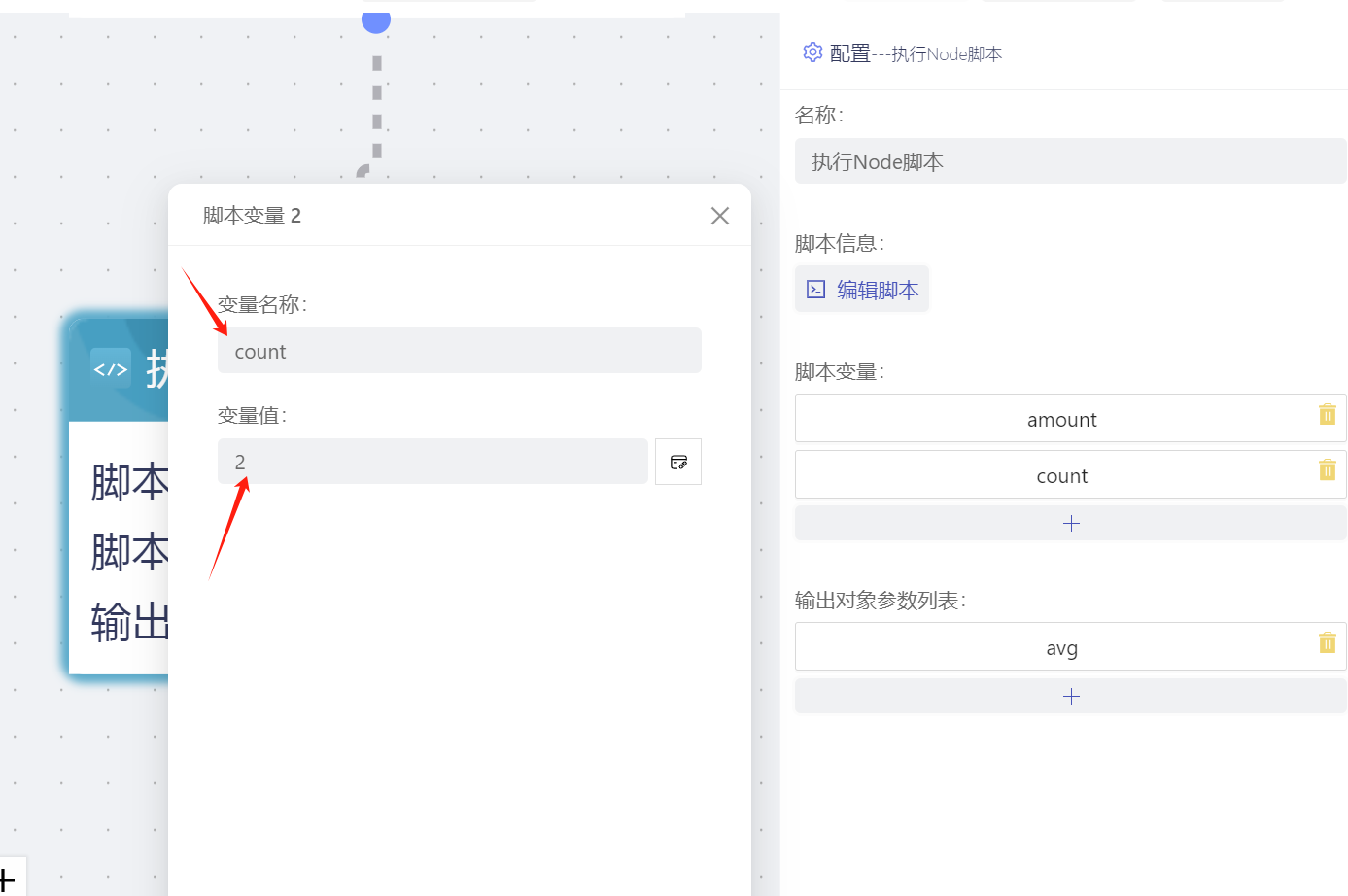
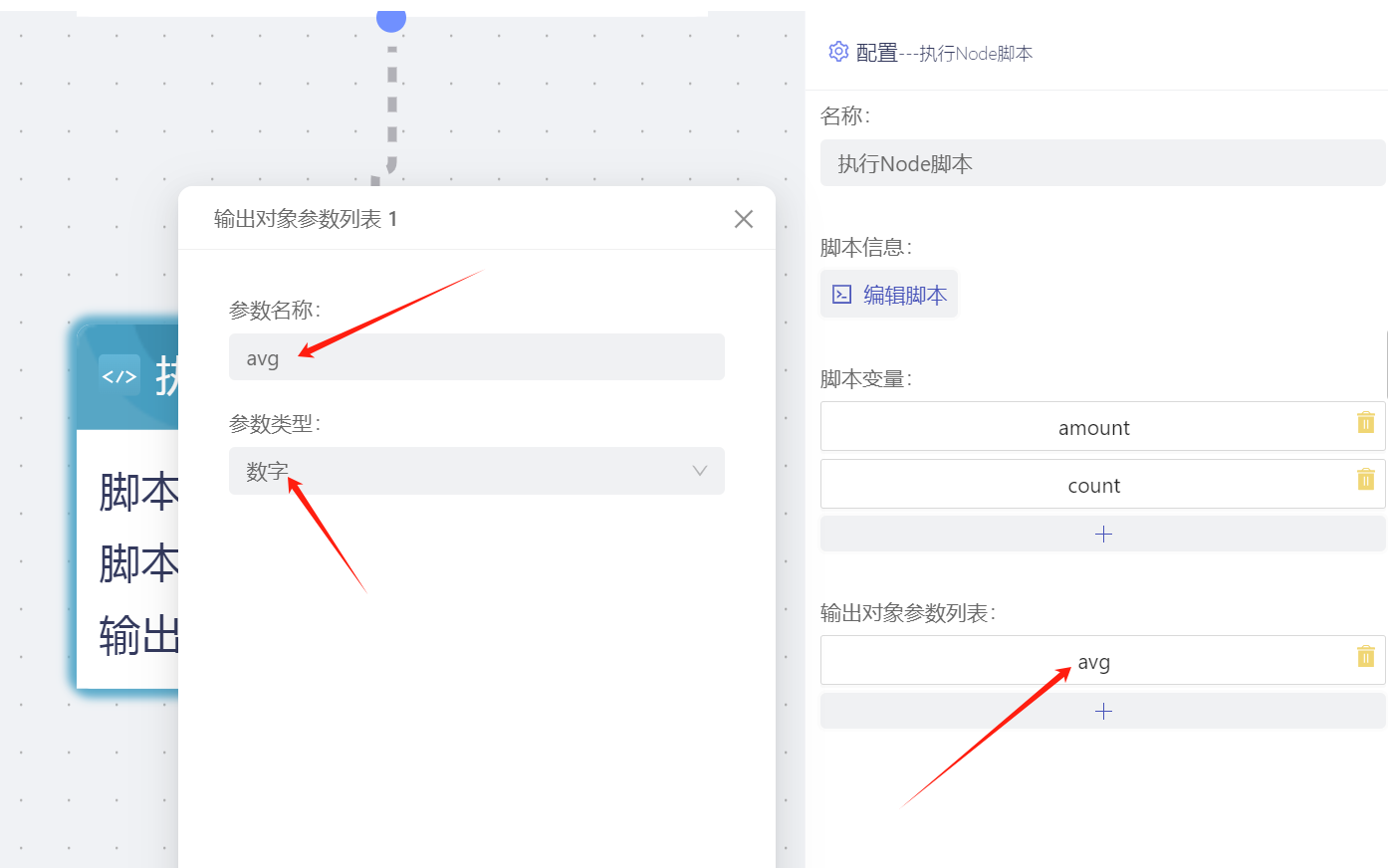
- 脚本内容解释,输出传入的两个变量,求商,作为结果输出。输出参数是一个对象,key为参数名称,value为输出值,类型必须与输出参数中设置的类型一致。

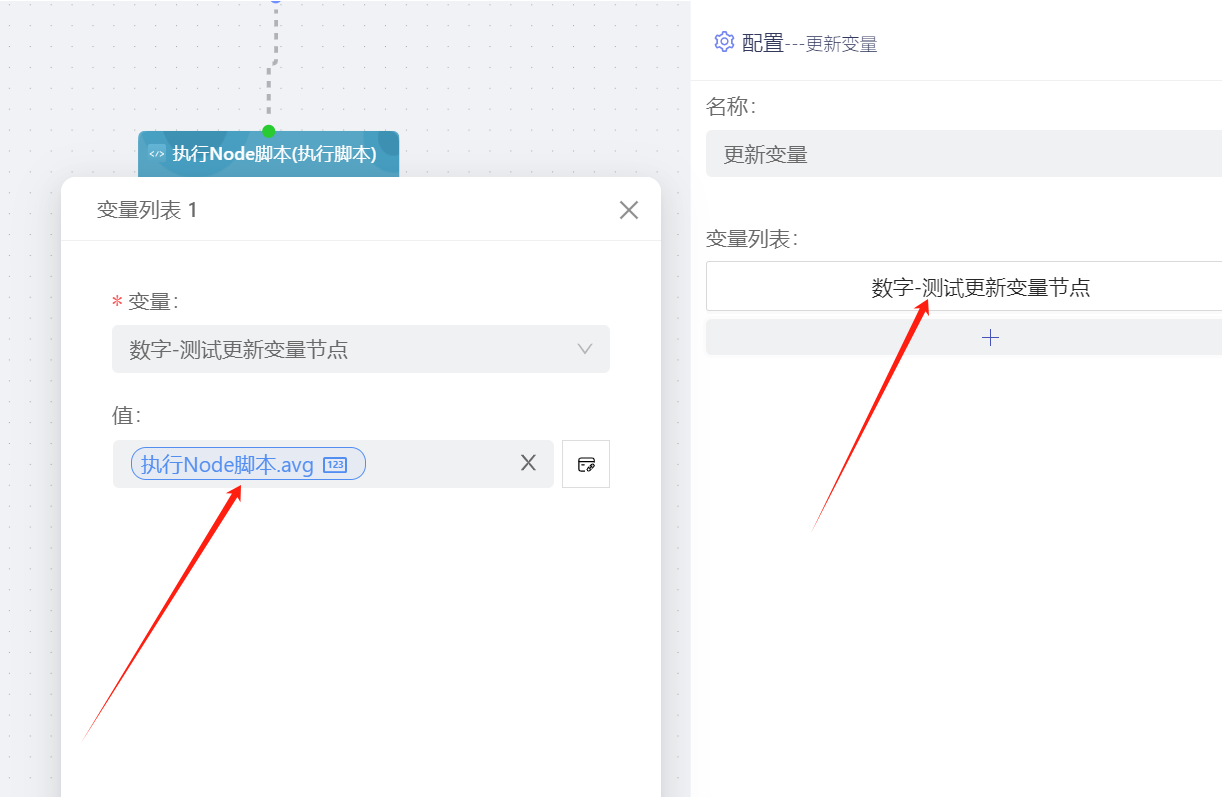
- 更新变量节点绑定脚本输出参数avg,然后更新到数据字典的系统变量(数字-测试更新变量节点)上。
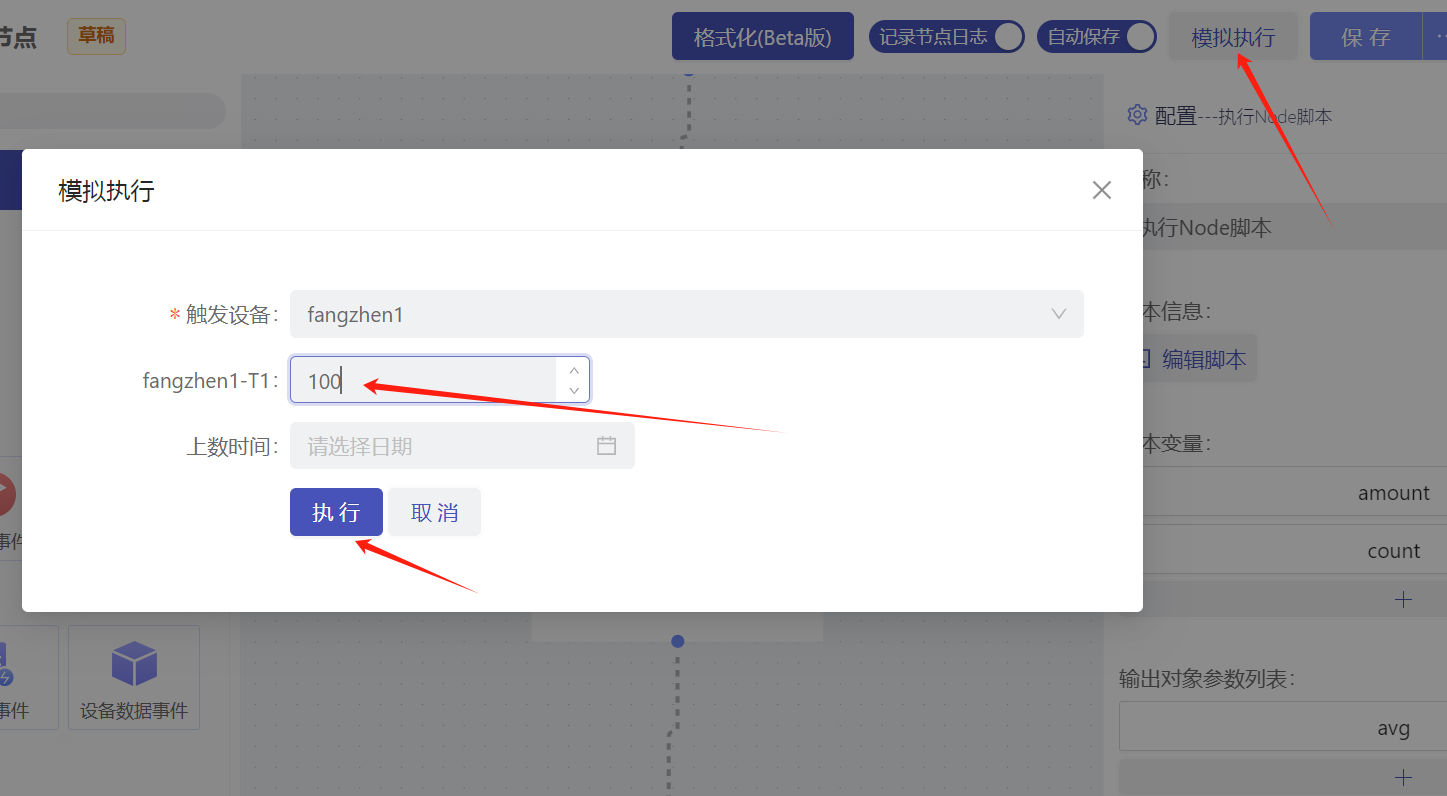
- 通过模拟触发展示效果,数据点值是100,即amount是100,count是2,脚本输出avg是50。
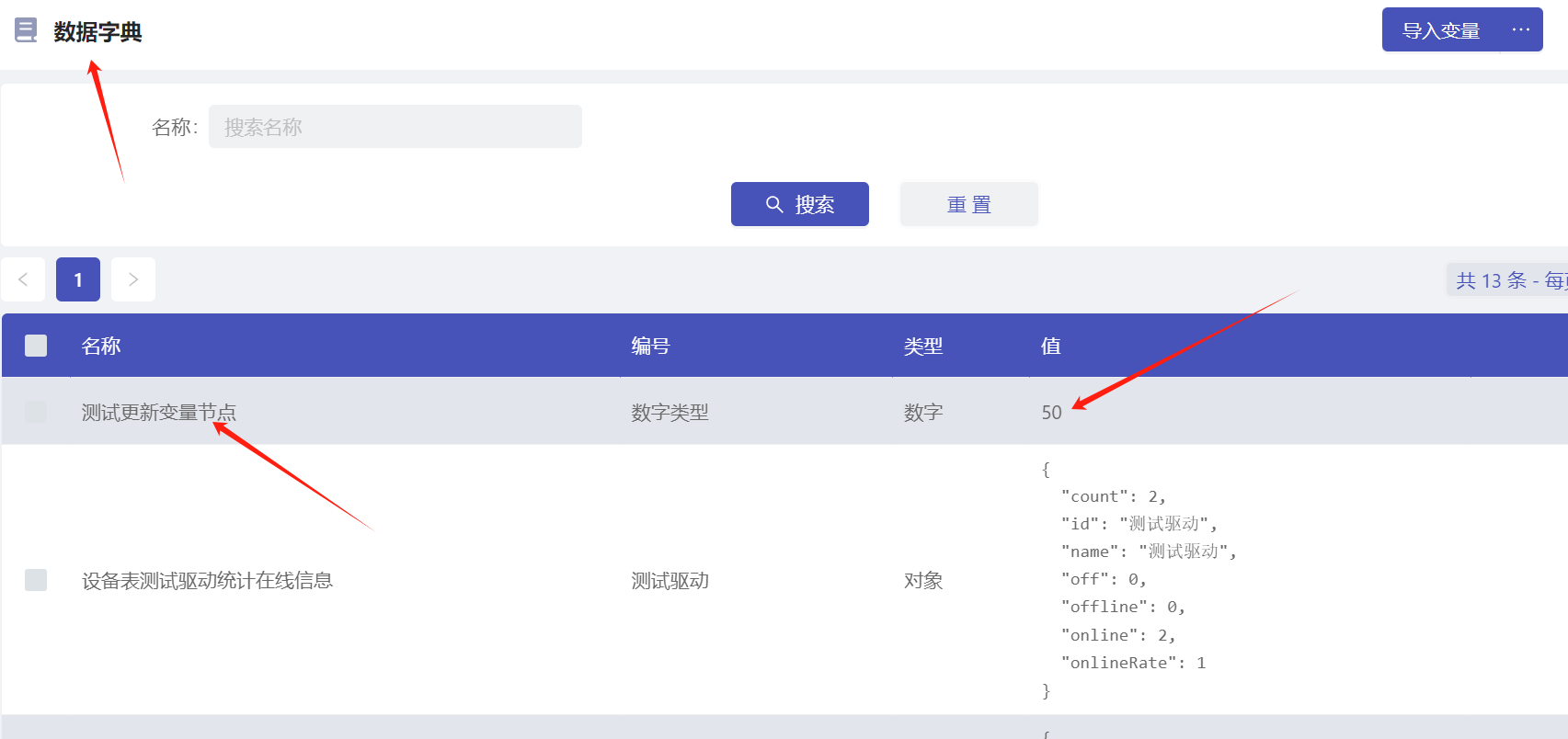
- 通过设备数据事件节点触发流程,把数据点的值传给脚本节点,执行脚本逻辑后,把结果输出给更新变量节点,达到修改平台数据字典中的系统变量的值的效果。
Python 脚本节点
该节点用于执行自己编写的 python 脚本,支持的 python 版本为 3.x, 在使用该节点前需要确保平台中已经按装 flow-python-script 服务.
入口函数
脚本按必须要求定义入口函数, 该函数是流程执行脚本的入口, 其参数和返回值必须为 dict 类型,且函数名必须为 execute.
如下所示:
def execute(inputs: dict) -> dict:
"""
入口函数
:param inputs: 输入参数, 即添加的所有脚本变量. key 为变量名称, value 为变量输入的值或绑定的其它变量的值
:return: 脚本的输出结果, 即输出参数对象列表, 类型必须为 dict. key 为参数名称, value 为输出值, 类型必须与输出参数中设置的类型一致
"""
# 从输入参数中获取相关变量的值
amount = inputs["amount"]
count = inputs["count"]
# 执行自定义逻辑
avg = amount / count
# 将计算结果赋值给输出参数.
return {"avg": avg}
脚本中除了定义 入口函数 外, 还可以添加自定义函数作为辅助函数, 但流程执行脚本时只会调用入口函数, 其它函数不会被调用.
注: 不要在脚本中定义全局变量, 因为脚本的执行是在一个沙箱环境中, 无法保证同一脚本的多次执行使用同一个沙箱. 如果想要保存一些数据, 可以使用脚本内置的 平台接口客户端 将数据保存到平台的系统变量中.
第三方库
该节点中添加了一些常用的第三方库, 可以在脚本中直接引用. 第三方库列表如下:
numpy, certifi, cffi, cryptography, jsons, requests, six, scipy, urllib3, yarl
import numpy as np
def execute(inputs: dict) -> dict:
# Create a 2-D array, set every second element in
# some rows and find max per row:
x = np.arange(15, dtype=np.int64).reshape(3, 5)
x[1:, ::2] = -99
x
# array([[ 0, 1, 2, 3, 4],
# [-99, 6, -99, 8, -99],
# [-99, 11, -99, 13, -99]])
x.max(axis=1)
# array([ 4, 8, 13])
# Generate normally distributed random numbers:
rng = np.random.default_rng()
samples = rng.normal(size=2500)
samples
return {"samples": samples}
平台接口
脚本中提供了一些常用的平台接口客户端, 可以通过该客户端在脚本中调用平台相关接口. 平台接口对象为 clients, 可以直接在脚本中引用. 脚本中的客户端提供的接口如下:
def get_system_variable_by_id(self, id: str) -> any:
"""
根据系统变量ID获取系统变量
:param id: 系统变量ID
:return: 如果变量存在则返回变量值, 否则返回 None
"""
pass
def get_system_variable_by_uid(self, uid: str) -> any:
"""
根据系统变量UID获取系统变量
:param uid: 系统变量UID, 即编号
:return: 如果变量存在则返回变量值, 否则返回 None
"""
pass
def get_system_variables_by_uid(self, uids: list[str]) -> dict:
"""
根据系统变量 UID 列表批量查询系统变量信息
:param uids: 系统变量 UID 列表
:return: 系统变量字典, key 为系统变量 UID, value 为系统变量值
"""
pass
def create_system_variable(self, uid: str, name: str, data_type: str, value: any) -> str:
"""
新增系统变量
:param uid: 系统变量 UID, 即编号
:param name: 系统变量名称
:param data_type: 数据类型. 可选值: number, string, boolean, date, array, object
:param value: 系统变量值
:return: 如果创建成功, 返回系统变量的 ID, 否则抛出异常
"""
pass
def update_system_variable_value(self, uid: str, value: any):
"""
修改系统变量的值
:param uid: 系统变量 UID, 即编号
:param value: 修改后的值
:return:
"""
pass
def save_or_update_system_variable(self, uid: str, name: str, data_type: str, value: any):
"""
更新或创建系统变量. 如果系统变量存在则更新, 否则创建
:param uid: 系统变量 UID, 即编号
:param name: 系统变量名称
:param data_type: 数据类型. 可选值: number, string, boolean, date, array, object
:param value: 系统变量值
:return: 如果系统变量不存在, 返回新增的系统变量 ID, 否则返回已存在系统变量 ID
"""
pass
系统变量的数据类型取值可以为以下几种:
- number 数值
- string 字符串
- boolean 布尔值
- date 日期
- array 数组
- object 对象
示例脚本
def add(a: int, b: int) -> int:
"""自定义函数"""
return a + b
def execute(inputs: dict) -> dict:
"""入口函数"""
# 获取脚本绑定的输入参数
a = inputs["a"]
b = inputs["b"]
result = add(a, b)
# 调用平台接口, 将计算结果保存到系统变量中
clients.save_or_update_system_variable("add_result", "加法计算结果", "number", result)
# 将执行结果返回给流程, 以供后续节点使用
return {"result": result}
kafka节点
接受存储消息并根据kafka配置将消息分发给订阅者。
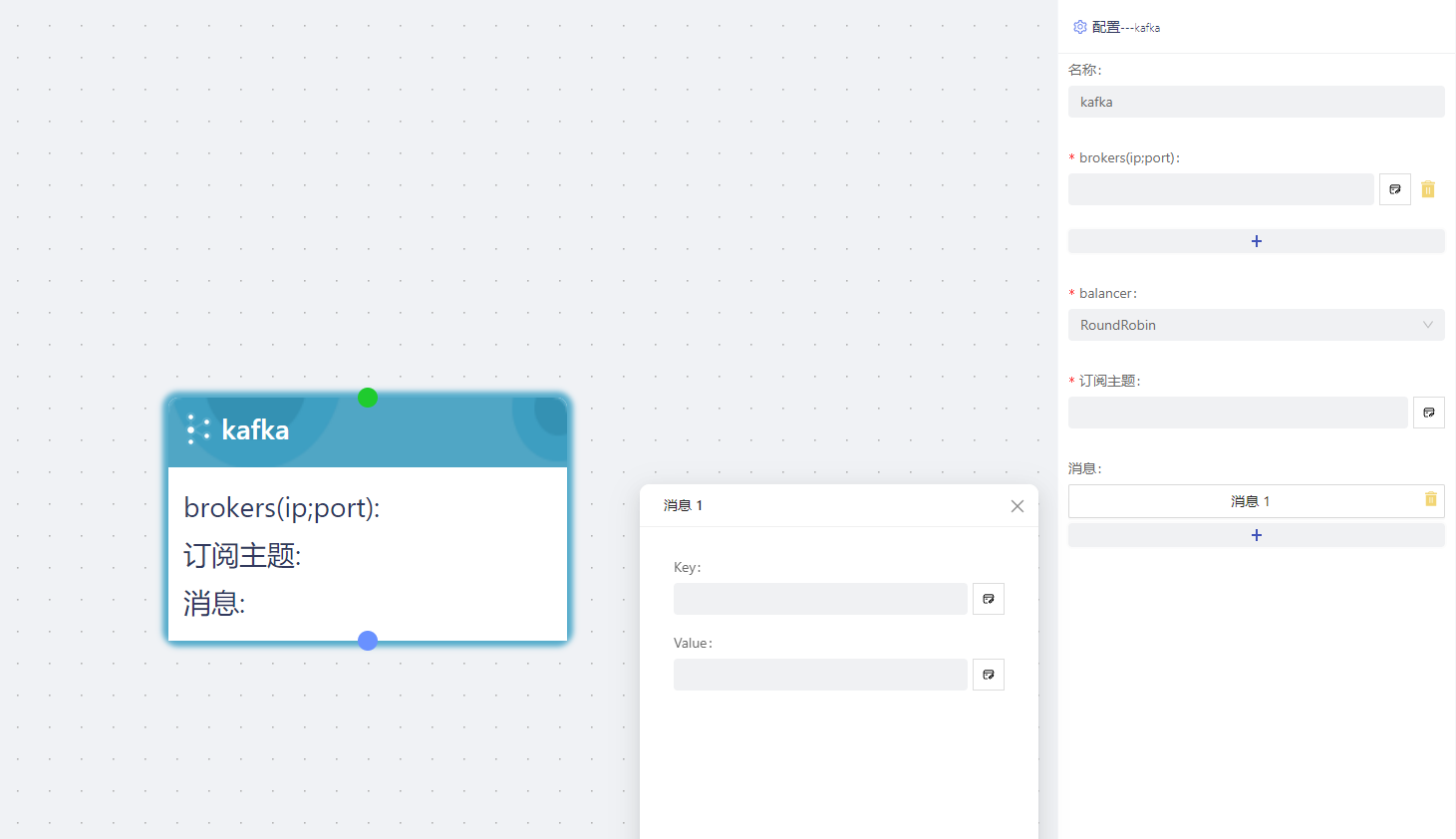
brokers(ip:port):可填写多个 brokers地址。
balancer:包括LeastBytes、Hash、ReferenceHash、CRC32Balancer、Murmur2Balancer、RoundRobin;选择时,默认为RoundRobin。
订阅主题:填写主题;
消息:填写小的key、Value。
AI模型
调用大语言模型,可对前项节点的数据经过AI模型生成有效的回应数据。
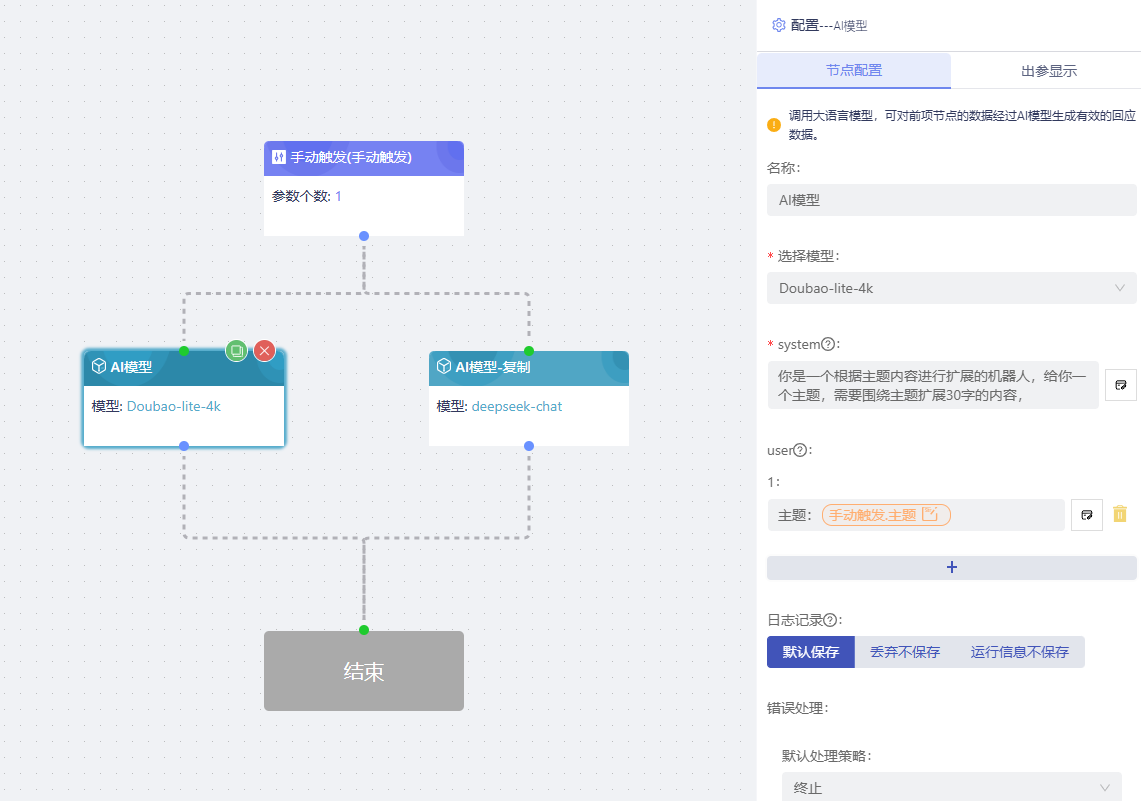
选择模型:必填项,选择系统设置中已添加的厂商模型,模型需具有一级分类标题(厂商名称)。当模型被禁用或移除时,下方会提示:“模型已失效,请重新选择”。
system:向模型提供指令、查询或任何基于文本的输入。
user:可以添加多个 user,向模型提供指令、查询或任何基于文本的输入。
示例:
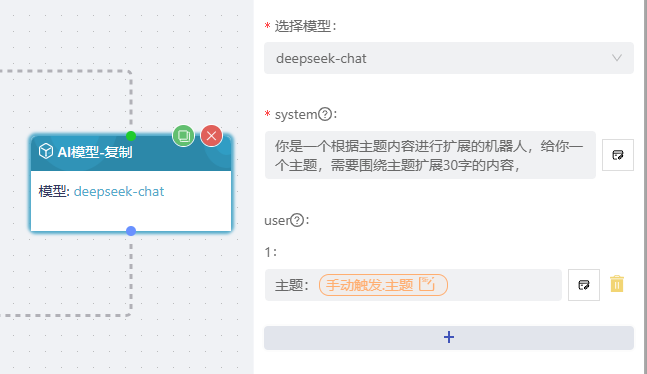
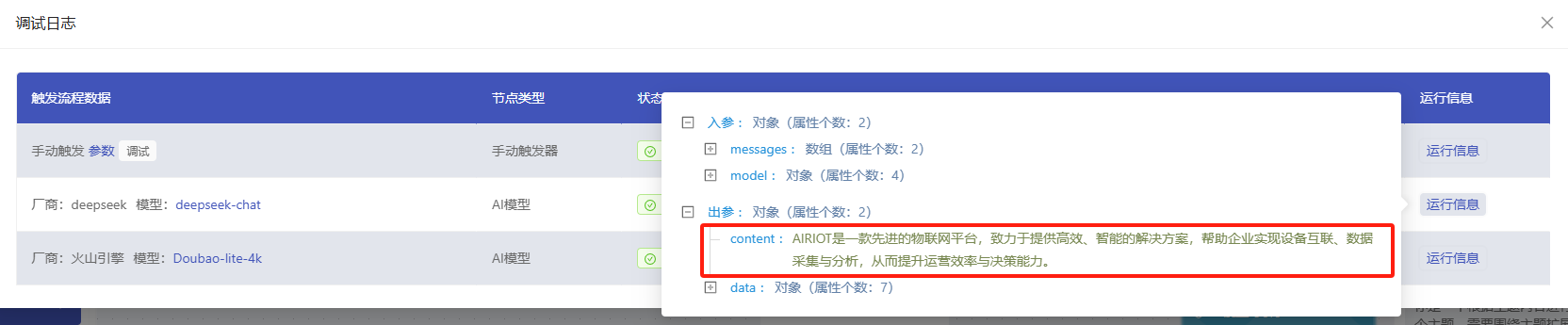
模型选择deepseek。
system:你是一个根据主题内容进行扩展的机器人,给你一个主题,需要围绕主题扩展30字的内容。
user:绑定前序输入的参数,如"AIRIOT" 。
输出结果如下所示,可供后续节点绑定: