平台接口客户端
介绍
平台客户端 SDK 用于访问平台接口,提供了平台接口的 Python 实现, 可以很方便实现第三方系统与平台的集成。平台客户端 SDK 中包括常用的 工作表数据管理、系统变量(数据字典)、数据点数据查询 等接口. 示例项目目上传至 https://github.com/air-iot/sdk-python-examples/tree/master/sdk-client-http-examples.
使用方式
1. 在项目中引入依赖
平台接口二次开发相关内容都在 client 子包内.
2. 初始化平台客户端
配置平台访问信息
使用平台客户端时, 需要提供平台的访问信息, 包括平台网关地址、授权信息等, 这些信息在创建客户端对象时需要.
平台网关地址默认为 http://IP:31000, 其中 IP 为部署平台服务器的IP地址, 端口默认为 31000.
授权信息为平台中提供的二次开发访问信息 appKey 和 appSecret.
当授权类型为 project 时, 只能访问该项目中的相关资源。 当授权类型为 tenant 时, 可以访问该租户下的所有项目内的资源。
关于如何创建二次开发应用授权, 请查看 二次开发-第三方应用添加。
创建客户端对象
在使用平台客户端之前, 需要创建客户端对象, 该对象包含了平台接口的访问地址、授权信息等。创建客户端对象示例如下:
from airiot_python_sdk.client.authentication import create_auth_from_etcd
from airiot_python_sdk.client.sync import SyncClients
# 创建客户端对象
# base_url 为平台网关地址, 例如: http://127.0.0.1:31000
# auth_type 为授权类型, 可选值为: tenant, project
# app_key 为二次开发应用的 appKey
# app_secret 为二次开发应用的 appSecret
# project_id 为项目ID, 当授权类型为 project 时, 该参数必填
clients = SyncClients(base_url = "http://127.0.0.1:31000", auth_type = "project",
app_key = "3b7f2831-0089-aa20-55b0-4ed1f65d21a9",
app_secret = "69ea13a9-bfb4-2276-c514-0d4a04c00354", project_id = "default")
3. 使用平台客户端
在上一步聚中创建了客户端对象 clients, 该对象是平台接口客户端集合, 通过该对象可以获取不同资源类型的客户端. 该对象包含的客户端接口如下:
class Clients:
"""
平台客户端列表, 用于获取各种资源的客户端
"""
def get_system_variable_client(self) -> SystemVariableClient:
"""
获取系统变量(数据字典)客户端. 该客户端用于操作系统变量(数据字典)
:return:
"""
pass
def get_latest_client(self) -> LatestClient:
"""
获取数据点最新数据客户端. 该客户端用于查询数据点的最新数据
:return:
"""
pass
def get_timing_data_client(self) -> TimingDataClient:
"""
获取时序数据查询客户端. 该客户端用于查询数据点的历史数据
:return:
"""
pass
def get_worktable_client(self) -> WorkTableDataClient:
"""
获取工作表操作客户端. 该客户端用于操作工作表数据
:return:
"""
pass
4. 统一响应格式说明
所有客户端接口方法统一返回 Response 结构, 结构如下:
class Response(Generic[T]):
"""
请求响应
"""
# 请求是否成功标识
success: bool = True
# 请求响应状态码. 请求成功时为200, 请求失败时为相应的业务错误码
code: int = 200
# 响应信息. 当请求失败时保存错误信息
message: str = "OK"
# 详细信息. 当请求失败时保存详细错误信息
detail: str = ""
# 字段名称. 当请求由于字段错误时保存字段名称. 例如: 参数字段校验失败
field: str = ""
# 请求响应数据
data: Optional[T] = None
@property
def full_message(self) -> str:
if self.detail is not None and len(self.detail) != 0:
return f"{self.message}, {self.detail}"
return self.message
5. 示例
下面以操作系统变量(数据字典)为例, 说明如何使用平台客户端.
# 创建客户端对象, 见步骤 2
# 获取系统变量客户端
sv_client = clients.get_system_variable_client()
# 创建系统变量
response = sv_client.create("default", SystemVariable(uid="maxScore", name="最高得分", type="number", value=99.5))
if not response.success:
raise Exception(f"创建系统变量失败, {response.full_message}")
# 查询数据变量的数据
response = sv_client.get_by_uid("default", "maxScore")
if not response.success:
raise Exception(f"查询系统变量失败, {response.full_message}")
elif not response.data or len(response.data) == 0:
raise Exception("未查询到系统变量")
print("最高得分:", response.data[0].value)
# 更新系统变量的值
response = sv_client.update_value("default", "maxScore", 99.7)
if not response.success:
raise Exception(f"更新系统变量的值失败, {response.full_message}")
# 删除系统变量
response = sv_client.delete_by_uid("default", "maxScore")
if not response.success:
raise Exception(f"删除系统变量失败, {response.full_message}")
客户端列表
系统变量(数据字典)
系统变量客户端提供对系统变量的增删改查等操作. 支持的操作如下:
class SystemVariableClient:
"""
系统变量(数据字典)客户端接口
"""
def get(self, project_id: str, query: Query, headers: Optional[dict[str, str]] = None) -> Response[
list[SystemVariable]]:
"""
自定义查询系统变量(数据字典)列表
:param headers: 自定义请求头
:param project_id: 项目ID
:param query: 查询参数
:return:
"""
pass
def get_by_id(self, project_id: str, id: str, headers: Optional[dict[str, str]] = None) -> Response[SystemVariable]:
"""
根据变量唯一标识获取系统变量信息
:param headers: 自定义请求头
:param project_id: 项目ID
:param id: 唯一标识
:return:
"""
pass
def get_by_uid(self, project_id: str, uid: str, headers: Optional[dict[str, str]] = None) -> Response[
list[SystemVariable]]:
"""
根据自定义变量标识获取系统变量信息
:param headers: 自定义请求头
:param project_id: 项目ID
:param uid: 自定义系统变量标识
:return:
"""
pass
def get_by_uids(self, project_id: str, uids: list[str], headers: Optional[dict[str, str]] = None) -> Response[
list[SystemVariable]]:
"""
根据自定义变量标识批量获取系统变量信息
:param project_id: 项目ID
:param uids: 自定义系统变量标识列表
:param headers: 自定义请求头
:return:
"""
pass
def get_by_name(self, project_id: str, name: str, headers: Optional[dict[str, str]] = None) -> Response[
list[SystemVariable]]:
"""
根据变量名称获取系统变量信息
:param headers: 自定义请求头
:param project_id: 项目ID
:param name: 系统变量名称
:return:
"""
pass
def get_by_names(self, project_id: str, names: list[str], headers: Optional[dict[str, str]] = None) -> Response[
list[SystemVariable]]:
"""
根据变量名称批量获取系统变量信息
:param headers: 自定义请求头
:param project_id: 项目ID
:param names: 系统变量名称列表
:return:
"""
pass
def create(self, project_id: str, variable: SystemVariable, headers: Optional[dict[str, str]] = None) -> Response[
InsertResult]:
"""
创建系统变量
:param headers: 自定义请求头
:param project_id: 项目ID
:param variable: 系统变量信息
:return:
"""
pass
def update(self, project_id: str, variable: SystemVariable, headers: Optional[dict[str, str]] = None) -> Response:
"""
更新系统变量
:param headers: 自定义请求头
:param project_id: 项目ID
:param variable: 系统变量信息
:return:
"""
pass
def update_value(self, project_id: str, id: str, value: any, headers: Optional[dict[str, str]] = None) -> Response:
"""
更新系统变量值
:param headers: 自定义请求头
:param project_id: 项目ID
:param id: 系统变量唯一标识
:param value: 系统变量值
:return:
"""
pass
def delete(self, project_id: str, id: str, headers: Optional[dict[str, str]] = None) -> Response:
"""
删除系统变量
:param headers: 自定义请求头
:param project_id: 项目ID
:param id: 系统变量唯一标识
:return:
"""
pass
def delete_by_uid(self, project_id: str, uid: str, headers: Optional[dict[str, str]] = None) -> Response:
"""
根据系统变量 UID 删除系统变量
:param project_id: 项目ID
:param uid: 系统变量 UID
:param headers: 自定义请求头
:return: 删除结果
"""
pass
工作表记录
工作表记录客户端提供了对工作表内数据的增删改查等操作. 支持的操作如下:
class WorkTableDataClient:
"""
工作表数据操作客户端
"""
def query(self, project_id: str, table_id: str, query: Query, headers: Optional[dict[str, str]] = None) -> Response[
list[dict]]:
"""
查询工作数据
:param project_id: 项目ID
:param table_id: 工作表标识
:param query: 查询信息
:param headers: 自定义请求头
:return:
"""
pass
def query_by_id(self, project_id: str, table_id: str, row_id: str, headers: Optional[dict[str, str]] = None) -> Response[dict]:
"""
根据记录ID查询工作表记录
:param project_id: 项目ID
:param table_id: 工作表标识
:param row_id: 记录ID
:param headers: 自定义请求头
:return: 如果记录存在, 返回记录信息
"""
def create(self, project_id: str, table_id: str, data, headers: Optional[dict[str, str]] = None) -> Response[
InsertResult]:
"""
向工作表中写入一条记录
:param project_id: 项目ID
:param table_id: 工作表标识
:param data: 记录数据. 可以为自定义对象, dict 或 str
:param headers: 自定义请求头
:return: 写入成功, 返回新增记录的ID
"""
pass
def create_batch(self, project_id: str, table_id: str, data, headers: Optional[dict[str, str]] = None) -> \
Response[BatchInsertResult]:
"""
批量向工作表中写入数据
:param project_id: 项目ID
:param table_id: 工作表标识
:param data: 记录数据列表, 必须为 list 或 str
:param headers: 自定义请求头
:return: 写入成功, 返回新增记录的ID
"""
pass
def update(self, project_id: str, table_id: str, row_id: str, data,
headers: Optional[dict[str, str]] = None) -> Response:
"""
更新工作表中记录
:param project_id: 项目ID
:param table_id: 工作表标识
:param row_id: 记录ID
:param data: 更新数据, 可以为自定义对象, dict 或 str
:param headers: 自定义请求头
:return:
"""
pass
def update_many(self, project_id: str, table_id: str, filter_query: Query, data,
headers: Optional[dict[str, str]] = None) -> Response:
"""
批量更新表中记录. 会更新所有匹配的记录, 如果过滤条件为空, 则会更新表中所有的数据
:param project_id: 项目ID
:param table_id: 工作表标识
:param filter_query: 更新记录过滤器, 只会使用 Query 对象中的 filter 信息
:param data: 更新的数据, 可以为自定义对象, dict 或 str
:param headers: 自定义请求头
:return:
"""
pass
def delete_by_id(self, project_id: str, table_id: str, row_id: str,
headers: Optional[dict[str, str]] = None) -> Response:
"""
根据记录ID删除表中记录
:param project_id: 项目ID
:param table_id: 工作表标识
:param row_id: 记录ID
:param headers: 自定义请求头
:return:
"""
def delete(self, project_id: str, table_id: str, filter_query: Query,
headers: Optional[dict[str, str]] = None) -> Response:
"""
批量删除工作表中记录. 会删除所有匹配的记录, 如果过滤条件为空, 则会删除表中所有的数据
:param project_id: 项目ID
:param table_id: 工作表标识
:param filter_query: 删除记录过滤器, 只会使用 Query 对象中的 filter 信息
:param headers: 自定义请求头
:return:
"""
pass
最新数据查询
最新数据查询客户端提供了对数据点最新数据的查询操作, 支持对资产内指定数据点的查询、多个数据点的查询以及不同资产数据点的查询. 支持的操作如下:
class LatestClient:
"""
查询数据点最新数据客户端接口
"""
def get(self, project_id: str, query: LatestQueries, headers: Optional[dict[str, str]] = None) -> Response[
list[LatestData]]:
"""
查询数据点最新数据
:param project_id: 项目ID
:param query: 查询的设备和数据点信息
:param headers: 自定义请求头
:return:
"""
pass
def get_by_device_id(self, project_id: str, table_id: str, device_id: str,
headers: Optional[dict[str, str]] = None) -> Response[
list[LatestData]]:
"""
根据设备编号查询所有数据点最新数据
:param project_id: 项目ID
:param table_id: 资产所属工作表标识
:param device_id: 设备编号
:param headers: 自定义请求头
:return:
"""
pass
def get_device_tag(self, project_id: str, table_id: str, device_id: str, tag_id: str,
headers: Optional[dict[str, str]] = None) -> Response[
list[LatestData]]:
"""
根据设备编号和数据点标识查询最新数据
:param project_id: 项目ID
:param table_id: 资产所属工作表标识
:param device_id: 设备编号
:param tag_id: 数据点标识
:param headers: 自定义请求头
:return:
"""
pass
def get_device_tags(self, project_id: str, table_id: str, device_id: str, tag_ids: list[str],
headers: Optional[dict[str, str]] = None) -> Response[
list[LatestData]]:
"""
查询一个设备下多个数据点的最新数据
:param project_id: 项目ID
:param table_id: 资产所属工作表标识
:param device_id: 设备编号
:param tag_ids: 数据点标识列表
:param headers: 自定义请求头
:return:
"""
pass
def get_every_device(self, project_id: str, table_id: str, device_ids: list[str], tag_id: str,
headers: Optional[dict[str, str]] = None) -> Response[list[LatestData]]:
"""
查询多个设备的同一个数据点的最新数据
:param project_id: 项目ID
:param table_id: 资产所属工作表标识
:param device_ids: 设备编号列表
:param tag_id: 数据点标识
:param headers: 自定义请求头
:return:
"""
pass
查询条件说明
class LatestQuery:
"""
查询数据点最新数据请求参数. 查询时, 可以查询设备下所有数据点的最新数据, 也可以查询指定数据点的最新数据.
如果查询设备下所有数据点的最新数据, 需要设置 allTags 为 true. 如果查询指定数据点的最新数据, 需要设置 tagId 为目标数据点标识.
如果要查询设备的部分数据点的最新数据, 可以添加多个 LatestQuery 对象到数组中.
例如: [LatestQuery("SN001", tag_id: "tag1"), LatestQuery("SN001", tag_id: "tag2")]
Attributes:
tableId: 资产所属工作表标识, 必填.
id: 资产编号, 必填.
allTag: 查询所有数据点时设置为 True, 选填.
tagId: 查询指定数据点时设置为目标数据点的标识, 选填.
"""
# 资产所属工作表标识
tableId: str
# 资产编号
id: str
# 是否查询该设备下所有数据点
allTag: Optional[bool] = None
# 数据点标识
tagId: Optional[str] = None
class LatestQueries:
queries: list[LatestQuery]
def __init__(self, queries: list[LatestQuery] = None):
self.queries = [] if not queries else queries
def append(self, query: LatestQuery):
self.queries.append(query)
查询结果说明
每个数据点的数据为一条记录, 查询结果为多条记录组成的列表. 每条记录的结构如下:
class LatestData:
"""
数据点最新数据查询结果. 查询结果中包含了数据点的标识, 最新数据的时间戳和值.
Attributes:
tableId: 资产所属工作表标识
id: 资产编号
tagId: 数据点标识
time: 最新数据的时间戳
value: 最新数据的值. 如果该数据点没有数据, 则为 None
"""
# 资产所属工作表标识
tableId: str
# 资产编号
id: str
# 数据点标识
tagId: str
# 时间戳(ms)
time: int
# 最新数据的值
value: any
历史数据查询
历史数据查询客户端用于查询数据点的历史数据信息, 支持的操作如下:
class TimingDataClient:
"""
时序数据查询客户端
"""
def query(self, project_id: str, query: TimingDataQueries, headers: Optional[dict[str, str]] = None) -> Response[
TimingData]:
"""
查询时序数据
:param project_id: 项目ID
:param query: 查询信息
:param headers: 自定义请求头
:return:
"""
pass
查询条件说明
为了方便构造查询条件, SDK 中提供了 TimingDataQueries 类来构造查询条件, 内容如下:
class Builder:
"""
时序数据查询构建器
"""
def select(self, *fields: str) -> 'Builder':
"""
查询的字段列表
:param fields: 字段名称列表
:return:
"""
pass
def select_as(self, field: str, alias: str) -> 'Builder':
"""
设置查询字段及别名. 例如: select_as("max(\"score\")", "maxScore")
:param field: 字段名称
:param alias: 别名
:return:
"""
pass
def table(self, table_id: str) -> 'Builder':
"""
设置要查询的工作表标识. 该字段为必填项
:param table_id: 工作表标识
:return:
"""
pass
def device(self, device_id: str) -> 'Builder':
"""
设置要查询的资产编号
:param device_id: 资产编号
:return:
"""
pass
def department(self, *departments: str) -> 'Builder':
"""
设置查询的资产所属部门
:param departments: 部门ID列表
:return:
"""
pass
def eq(self, tag: str, value: any) -> 'Builder':
"""
相等条件
:param tag: 数据点或标签名称
:param value: 比较值
:return:
"""
pass
def not_eq(self, tag: str, value: any) -> 'Builder':
"""
不相等条件
:param tag: 数据点或标签名称
:param value: 比较值
:return:
"""
pass
def lt(self, tag: str, value: any) -> 'Builder':
"""
小于条件
:param tag: 数据点或标签名称
:param value: 比较值
:return:
"""
pass
def lte(self, tag: str, value: any) -> 'Builder':
"""
小于等于条件
:param tag: 数据点或标签名称
:param value: 比较值
:return:
"""
pass
def gt(self, tag: str, value: any) -> 'Builder':
"""
大于条件
:param tag: 数据点或标签名称
:param value: 比较值
:return:
"""
pass
def gte(self, tag: str, value: any) -> 'Builder':
"""
大于等于条件
:param tag: 数据点或标签名称
:param value: 比较值
:return:
"""
pass
def time_between(self, start_time: datetime, end_time: datetime) -> 'Builder':
"""
设置时间范围
:param start_time: 开始时间
:param end_time: 结束时间
:return:
"""
pass
def start_time(self, start_time: datetime) -> 'Builder':
"""
设置开始时间
:param start_time: 开始时间
:return:
"""
pass
def end_time(self, end_time: datetime) -> 'Builder':
"""
设置结束时间
:param end_time: 结束时间
:return:
"""
pass
def since(self, since: str, contains_start_time: bool = False) -> 'Builder':
"""
设置查询最近一段时间的数据
:param since: 时间段. 例如: 1d 表示 1 天, 1h 表示 1 小时, 1m 表示 1 分钟
:param contains_start_time: 是否包含开始时间
:return:
"""
pass
def group_by(self, column: str) -> 'Builder':
"""
设置分组条件
:param column: 分组字段
:return:
"""
pass
def group_by_device(self) -> 'Builder':
"""
按资产分组
:return:
"""
pass
def group_by_time(self, interval: str) -> 'Builder':
"""
按时间段分组
:param interval: 时间段. 例如: 1h 表示 1 小时, 1d 表示 1 天
:return:
"""
pass
def with_fill(self, value: str) -> 'Builder':
"""
设置填充方式
:param value: 填充方式. 可选值: none, null, previous, value 等
:return:
"""
pass
def order_by_time_desc(self) -> 'Builder':
"""
按时间降序排序
:return:
"""
pass
def order_by_time_asc(self) -> 'Builder':
"""
按时间升序排序
:return:
"""
pass
def order_by_asc(self, field: str) -> 'Builder':
"""
按指定字段升序排序
:param field: 字段名称
:return:
"""
pass
def order_by_desc(self, field: str) -> 'Builder':
"""
按指定字段降序排序
:param field: 字段名称
:return:
"""
pass
def with_limit(self, limit: int) -> 'Builder':
"""
限制查询的记录数量
:param limit: 记录数量
:return:
"""
pass
def with_offset(self, offset: int) -> 'Builder':
"""
设置返回记录的偏移量
:param offset: 偏移量
:return:
"""
pass
示例
query = (TimingDataQueries.new_builder()
# 设置查询的工作表, 即目标设备数据所在工作表的标识. 该字段为必填项
.table("opcua130")
# 查询的字段列表
.select("id", "key1", "key2", "key3")
# 查询的时间范围, 例如: 查询最近 7 天的数据
.since("7d")
# 将数据按设备进行分组
.group_by_device()
.finish()
.build())
注意事项: table 用于设置查询数据所在工作表的标识, 该字段为必填项
其它
客户端 SDK 中提供了一些工具类, 用于简化和辅助开发。
查询构造器
客户端接口中的很多查询接口, 其结构比较复杂, 不易构造且容易出错, 为此 SDK 中提供了一个查询构造器 Query 来简化查询条件的构造.
查询参数的整体结构如下所示:
{
"project": {},
"filter": {},
"sort": {},
"limit": 30,
"skip": 20,
"withCount": true
}
字段说明如下:
project查询请求需要返回的字段列表. 例如:{"id": 1, "name": 1, "address": {"city": 1}}.key为字段名,value为1或Map. 如果为为一级字段需要设置为1例如:{"id": 1, "name": 1}, 如果要返回嵌套对象内的字段, 则需要设置为Map, 例如:{"address": {"city": 1}}filter查询条件, 如果没有添加任何条件则查询全部数据.key为字段名,value为过滤的值或逻辑运算符, 例如:{"name": "Tom", "age": {"$gt": 20, "$lt": 30}}.sort排序条件,key为字段名,value为1表示升序,-1表示降序, 例如:{"age": 1, "name": -1}.limit查询结果的最大数量, 可用于分页查询或限制返回的记录数量.skip查询结果的偏移量, 即忽略前 N 记录, 可用于分页查询.withCount是否返回符合条件的记录总数, 如果为true则会在查询结果记录数量会保存在响应对象ResponseDTO<T>中的count字段.
注意事项
- 如果查询条件需要使用逻辑或, 可以在
filter中添加$or字段, 其值为Map<String, Object>结构与filter一致, 任一条件成立时表示记录匹配. - 如果同一字段存在多个逻辑条件, 则需要将多个条件放在一个
Map中, 例如:{"age": {"$gt": 20, "$lt": 30}}, 表示查询20 < age < 30的记录.
逻辑运算符
| 符号 | 说明 | 示例 |
|---|---|---|
| $not | 不相等, 与 SQL 中的 <> 作用相同 | {"age": {"$not": 18}} |
| $in | 在指定列表内, 与 SQL 中的 in 作用相同 | {"id": {"$in": [1,3,4]}} |
| $nin | 不在指定列表内, 与 SQL 中的 not in 作用相同 | {"id": {"$nin": [1,3,4]}} |
| $gt | 大于指定的值, 与 SQL 中的 > 作用相同 | {"age": {"$gt": 18}} |
| $gte | 大于等于指定的值, 与 SQL 中的 >= 作用相同 | {"age": {"$gte": 18}} |
| $lt | 小于指定的值, 与 SQL 中的 < 作用相同 | {"age": {"$lt": 18}} |
| $lte | 小于等于指定的值, 与 SQL 中的 <= 作用相同 | {"age": {"$lte": 18}} |
| $regex | 正则匹配, 与 SQL 中的 like 相似 | {"name": {"$regex": "张"}} |
示例
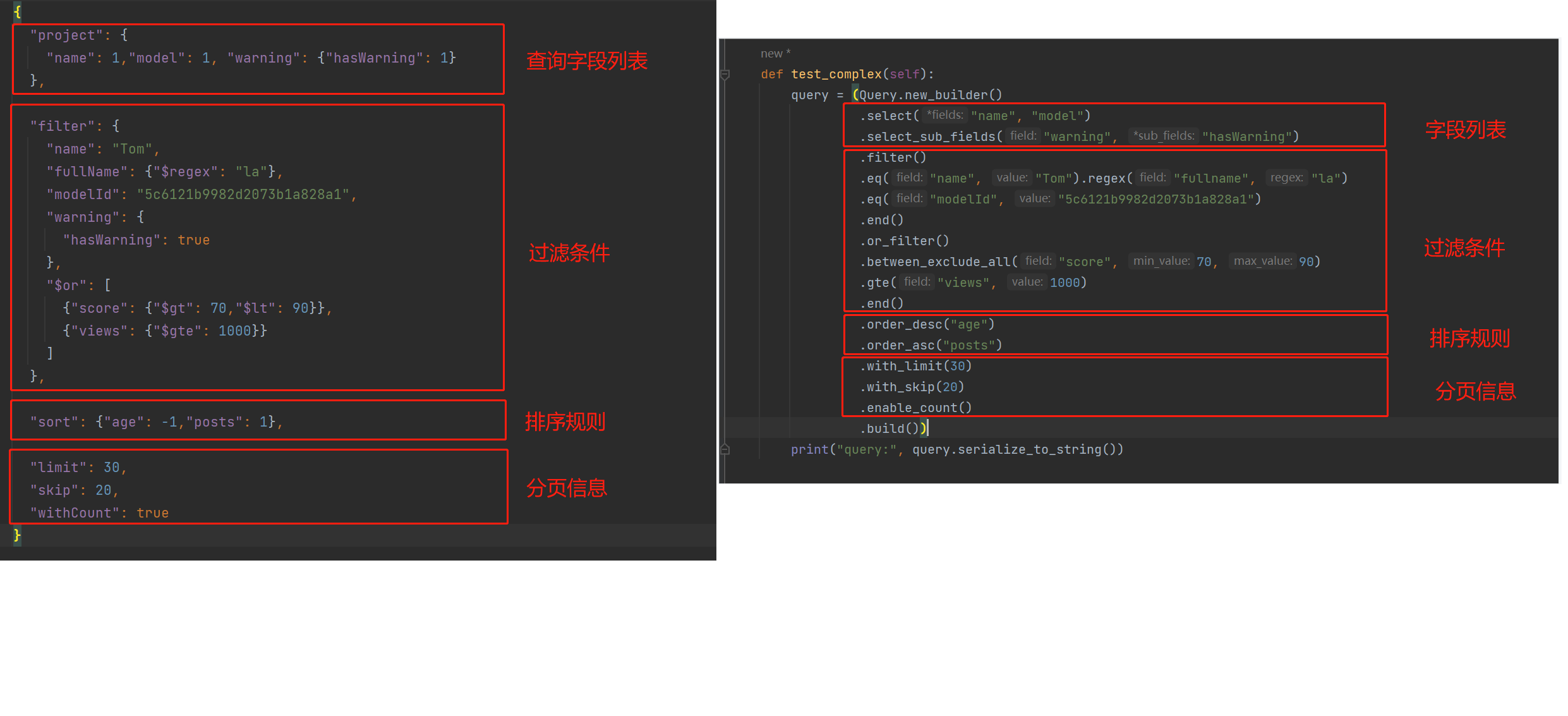
示例数据如下所示:
{
"project": {
"name": 1,
"model": 1,
"warning": {
"hasWarning": 1
}
},
"filter": {
"name": "Tom",
"fullname": {
"$regex": "la"
},
"modelId": "5c6121b9982d2073b1a828a1",
"warning": {
"hasWarning": true
},
"$or": [{
"score": {
"$gt": 70,
"$lt": 90
}
}, {
"views": {
"$gte": 1000
}
}]
},
"sort": {
"age": -1,
"posts": 1
},
"limit": 30,
"skip": 20,
"withCount": true
}
使用构造器创建上述查询条件的代码如下所示:
对照图